 运维自动化流程
运维自动化流程
# 1. 运维自动化
伴随着互联网以及大数据时代的到来,IT信息系统已经成为最重要的数据载体和信息来源, IT系统在企业内部的重要性日益突出;但是随着企业信息化程度的提高、IT环境规模的扩大和IT环境复杂度的增加、行业内服务竞争的加剧,如何保证IT系统安全稳定运行,为业务提供可持继性的支撑,最优化IT环境的性能,有效控制IT成本和计划IT投资,这些都对IT系统运行维护支持以及IT服务水平提出了新的要求和挑战。传统的IT运维管理平台已经不能满足互联网以及大数据时代运维需求,智能化是运维管理平台的发展方向,自动化是智能化运维的最佳实践。
在日常IT运维工作中存在大量重复的日常工作任务,这些任务有的简单繁琐数量大,有的严重依赖执行次序,有的需要等待各种条件具备之后方可执行,尽管IT运维管理的技术在不断进步,但实际上IT运维人员并未真正解放,目前许多企业的系统开启和关闭、系统更新升级、应急操作等绝大多数工作都是手工操作的。即便简单的系统变更或软件复制黏贴式的升级更新往往都需要运维人员逐一登录每台设备进行手工变更,云平台和大数据、海量设备的情况下,工作量之大可想而知。而这样的变更和检查操作在IT运维中往往每天都在进行,占用了大量的运维资源。通过智能化运维管理平台的自动化将帮助运维人员从简单重复的工作中得以解放。或许IT运维的自动化实践可以从以下几个方面开始:
# 1.1 日常巡检自动化
日常巡检工作是IT部门日常运维工作中每天都要定时执行的工作,巡检工作内容简单但是需要重复执行。占用了IT运维人员的大量工作时间。通过自动化巡检可以将硬件状态,设备负载,系统时间,磁盘空间,线路流量,数据库表空间使用率等进行自动巡检,并形成符合用户要求的巡检报告。
# 1.2 故障修复自动化
日常监控是传统IT运维软件的基本功能,告警明确后,就需要进行故障处理,将故障处理分为四个阶段:源头发现、告警确诊、修复授权和故障维修。在这四个阶段中源头发现和告警确诊主要将大量的告警进行收敛,将真正需要处理的告警进行明确化找到故障的跟原因(如一个业务进程僵死或者进程宕机)。在沟通授权阶段,当不能真正做到无需知会直接处理的时候,就必须进行人工干预和确认:故障维修将已经明确的故障跟原因的故障进行自动修复(例如重启服务进程),需要人工确认的故障修复需要人员参与半自动化修复。
# 1.3 容灾切换操作自动化
灾备中心切换是运维工作的一个重要组成部分,以容灾作业流程的方式实现容灾切换流程批量自动执行;从启动、IP切换、环境初始化、数据文件准备到应用程序启动和配置以及外围系统操作进行全面的控制,在灾难发生后的最短时间内实现灾备切换,降低损失。并且对主备中心物理环境到软件版本、关键配置文件进行一致性检查,确保两个环境的一致,防止灾备切换失效。
# 1.4 软件分发配置自动化
多应用系统Bug修复与厂商对产品的定期升级,会导致频繁的低风险变更,通过Server端发起批作业方式可自动实现大批量的软件、配置分发与安装部署。
通过向客户端下发备份脚本,备份业务数据、配置信息、环境参数,并停止客户端应用服务,然后批量下发新版本的安装配置文件、DLL文件等,最后启动客户端应用服务对应用的服务状态与相关日志信息进行检查,确认软件分发和配置工作成功完成。
# 1.5 运维学习和发展的一个线路:
搭建服务 (部署并运行起来)
用好服务 (监控、管理、优化)
自动化 (服务直接的关联和协同工作)
产品设计 (设计一个监控系统)
云计算的核心竞争力是运维
运维架构: 网络、数据库、系统、云计算、自动化、开发python、运维管理、服务管理、项目管理、测试、业务
专注于某一领域
机房运维 (负责设备上下架、巡检、报修、硬件监控)
监控运维 (7X24运维值班、故障处理)
基础设施运维 (系统安装、网络维护)
基础服务运维(包含运维开发) (内部DNS、负载均衡、系统监控、资产管理、运维平台)
应用运维 (项目上线、业务部署、版本管理、灰度发布)
系统运维 (架构层面的分布式缓存、分布式文件系统、环境规划(测试、开发、生产)、架构设计、性能优化)
安全运维 (整体的安全方案、规范、漏洞监测、安全防护)
# 2. 运维标准化
标准化是一切运维自动化的基础,无标准、不自动。所以自动化运维的前提条件是做好运维标准化工作。以下是自己总结的一些内容:
1、云端系统镜像(模板镜像命名规则)镜像一定要是干净的,如果不干净很有可能引起生产事故,包含各种服务客户端(如zabbix-agent、salt-minion) 2、系统优化标准参数、自动化一键优化脚本 3、操作系统命名规则site qa pre prd 4、软件安装版本标准化 5、软件安装目录标准化 6、应用系统名称命名规则、应用系统数据库命名规则 7、监控模板标准化、特殊监控特殊对待 8、综合管理机器 前期规划性能争取比较好,因为后期可能有很大性能需求 9、日志备份机器,磁盘以及性能尽量可能较高 10、ip地址管理(可以写脚本生产一个动态更新表) 11、自动化工具salt、ansible、Jenkins 12、监控标准化(基础cpu、内存、磁盘、网络流量、系统连接数、业务指标监控) 13、资源统计表标准化模板(云端ecs、slb、redis、rds...、专人负责统计、该员工负责资源开通、升配、降配) 14、运维各类实施文档(各种中间件部署、升级、问题解决) 15、安全审计-堡垒机或安全审计日志(密码+私钥访问) 16、权限标准化管理(专人负责) 17、自动化脚本编写 避免重复性工作,如创建用户 18、安全防护,云端ddos、waf,应用端如nignx有防sql注入、防爬虫等安全配置 19、端口统一规划表,需要统一管理 20、新开通资源第一时间增加监控、日志收集 22、运维制度或标准最小单元化,标准化最小单元化
其他:对于公司运维人员,一定要存在备份人员,杜绝某些系统只有某一位运维同学熟悉。这样容易导致人员离职,系统交接不到位,系统维护困难以及踩坑
# 2.1 物理设备层面:
1.服务器标签化、设备负责人、设备采购详情、设备摆放标准
2.网络划分、远程控制卡、网卡端口
3.服务器机型、硬盘、内存统一;根据业务分类
4.资产命名规范、编号规范、类型规范
5.监控标准
# 2.2 操作系统层面:
1.操作系统版本
2.系统初始化(DNS、NTP、内核参数调优、rsyslog、主机名规范)
3.基础Agent配备(Zabbix Agent、Logstash Agent、Saltstack minion)
4.系统监控标准(CPU、内存、硬盘、网络、进程)
# 2.3 应用服务层面:
1.Web服务器选型(Apache、Nginx)
2.进程启动用户、端口监听规范、日志收集规范(访问日志、错误日志、运行日志)
3.配置管理(配置文件规范、脚本规范)
4.架构规范(Nginx+Keepalived、LVS+Keepalived等等)
5.部署规范(位置、包命名等)
# 2.4 运维操作层面:
1.机房巡检流程(周期、内容、报修流程)
2.业务部署流程(先测试、后生产、回滚)
3.故障处理流程(紧急处理、故障升级、重大故障管理)
4.工作日志标准(如何编写工作日志)
5.业务上线流程(1.项目发起 2.系统安装 3.部署Nginx 4.解析域名 5.测试 6.加监控 7.备份)
6.业务下线流程(谁发起,数据如何处理)
7.运维安全规范(密码复杂度、更改周期、×××使用规范、服务登录规范)
# 2.5 总结:
标准化 (规范化 流程化 文档化)
目标:文档化
# 2.6 工具化:
SHELL脚本 (备份、部署、功能性(流程)脚本、检查性、报表性)
开源工具:ZABBIX,ELK,saltstack,cobbler
目标:
1、促进标准化的实施
2、将重复的操作简单化
3、将多次操作流程化
4、减少人为操作的低效和造成的故障
痛点:
1、你至少要SSH到服务器执行。可能犯错
2、多个脚本有执行顺序的时候,可能犯错。
3、权限不好管理,日志没法统计。
4、无法避免手工操作。
# 2.7 Web化
运维操作平台
例子:JOB管理平台
1、做成web界面
2、权限控制
3、日志记录
4、弱化流程
5、不用SSH到服务器,减少人为操作造成的故障
DNS web管理 bind-DLZ
负载均衡web管理
JOB管理平台
监控web管理 ZABBIX
操作系统安装web管理
# 2.8 服务化(API化)
DNS web管理 bind-DLZ dns-api
负载均衡web管理 slb-api
JOB管理平台 job-api
监控web管理 ZABBIX zabbix-api
操作系统安装web管理 cobbler-api
部署平台 deploy-api
配置管理平台 saltstack-api
自动化测试平台 test-api
1、调用cobbler-api安装操作系统
2、调用saltstack-api进行系统初始化
3、调用zabbix-api 将该新上线机器加上监控
4、再次调用saltstack-api 部署软件
5、调用deploy-api 将当前版本的代码部署到服务器上
6、调用test-api 测试当前服务运行是否正常
7、调用slb-api 将该节点加入集群
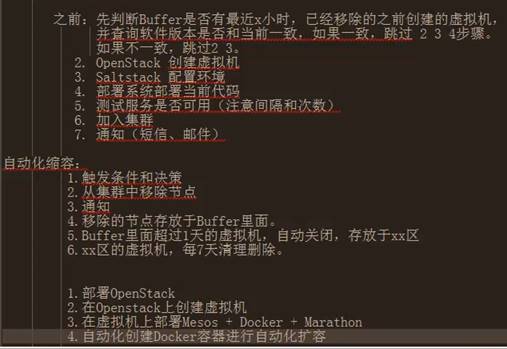
# 2.9 智能化
智能化的自动化扩容、缩容、服务降级、故障自愈
触发机制--》决策系统--》
触发:
1、当某个集群的访问量超过最大支撑量,比如10000
2、并持续5分钟
3、不是攻击
4、资源池有可用资源
4.1 当前网络带宽使用率
4.2 如果 是公有云--钱够不够
5、当前后端服务支持量是否超过阈值 如果超过应该后端 先扩容
6、数据是否可以支持当前并发
7、当前 自动化扩容队列,是否有正在扩容的节点
8、其它业务相关的
基于ITIL的IT运维管理体系
服务是向客户提供价值的一种手段,使客户不用承担特定的成本和风险就可以获得所期望的结果
先有ITSM,后有ITIL
ITIL是ITSM的最佳实践

成为一名运维经理:ITIL PMP



# 3. 代码上线流程
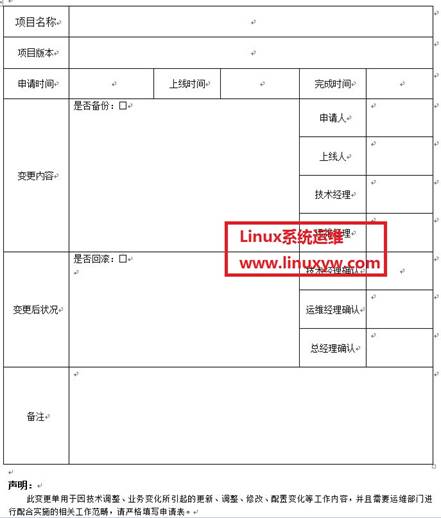
填写申请单 填写《XXX运营系统变更、上线申请单》 请严格按申请单内容进行填写
顶目名称:顶目名称,如 Linux运维
项目版本:版本号
申请时间:需在工作日13点前作出申请
上线时间:由运维经理指定上线时间(一般是工作日下午17点左右,紧急情况例外)
完成时间:代码上线所有操作完成时间(代码上线、回滚,确认)
变更内容:需申请人对此处上线引起的结构、内容等变化,详细记录
申请人:填写申请代码上线人的姓名
上线人:填写服务器操作人的姓名(由运维经理指定)
技术经理:技术经理亲笔签名
运维经理:运维经理亲笔签名
变更后状况:填写代码上线后的状况(如是否正确,是否引起BUG等),需申请人详细填写
技术经理确认:技术经理亲笔签名
运维经理确认:运维经理亲笔签名
总经理确认:总经理亲笔签名
其它备注:
申请人填写(项目名称、版本号、申请时间、变更内容,申请人)此单后,交给技术经理审批,技术经理审批通过则在技术经理处签上自己名字,再转交给运维经理,运维经理确认技术经理签名后,指定一个运维人员作为上线人协助此次代码上线的操作和指定代码上线时间,并在运维经理处亲笔签名,最后此单转交给申请人。
当代码上线后,需测试一段时间,如果一切正常,申请人在变更后状况处填写一切正常;如果引起BUG等问题,则需详细记录这些问题(如果代码回滚,需在是否回滚处打勾)。最后此单再交给技术经理、运维经理、总经理确认并签名,然后此单放公司存档。
运维经理需看到技术经理亲笔签名后,才可受理此单
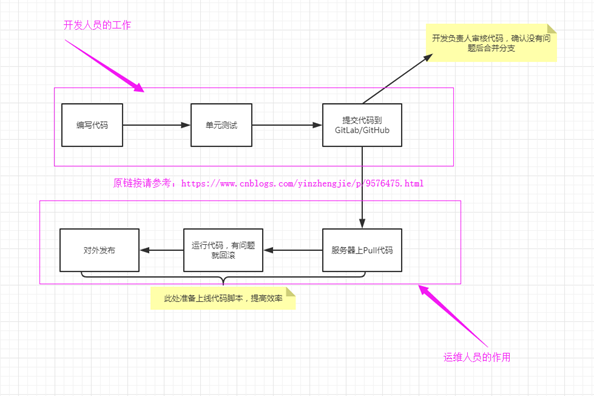
运维人员上线操作流程: 1:在上线前,需对程序文件和数据库 (opens new window)文件进行备份(备份名字需带上当前时间,如linuxyw20130621.tar.gz),如果遇到严重BUG,立即进行代码回滚操作。 2:使用SVN进行代码上线。代码上线后,会在test目录,由IP:port进行测试,测试没有问题后,上线人员再把更新的内容推到正式目录中,并在正式环境中进行检测 附:代码上线需经过以下流程: A:程序在办工室本地环境测试,由开发部门进行内测 有问题:继续修改 B:内测正确后,申请上线,填写《XXXX运营系统变更、上线申请单》 C:运维部门协助开发部门使用SVN进行代码上线,然后进行IDC环境测试,由开发部,运维部,编辑部负责测试。测试环境通过IP:port访问。 有问题:返回继续修改 D:IDC环境测试通过,则由运维上线人员把更新程序推送到正式目录中,由开发部,运维部,编辑部负责最后测试,无问题,代码上线结束,申请人完善《XXXX运营系统变更、上线申请单》并提交。 有问题:代码回滚;返回继续修改
获取代码===>编译java代码===>配置文件放入密码文件修改===>打包====>拷贝到目标服务器===>集群中移除节点===>解压===>放入部署目录===>拷贝差异文件===>重启==>测试 ===>加入集群
- 测试环境
- 固定的上线时间以及次数
- 上线要做好失败准备 -- 回滚(mv、软连接)
# 3.1 运维需要运行代码,检查是否可以正常运行
代码上线处理步骤:
2.1>.当你测试代码运行失败时,需要找开发解决问题;
2.2>.当你测试代码运行成功时,需要告知你的上司,当公司的领导说可以上线了,你才能上线代码;
2.3>.当上线代码时,你应该讲之前稳定的代码进行备份;
2.4>.上线新的代码,加入生成环境中出现不稳定的状况,需要及时复原之前的数据,这个时候你备份的操作就显得尤为重要;
2.5>.这些操作你可以写成脚本来完成,当然你也可以使用git+Jenkins来实现代码自动发布;
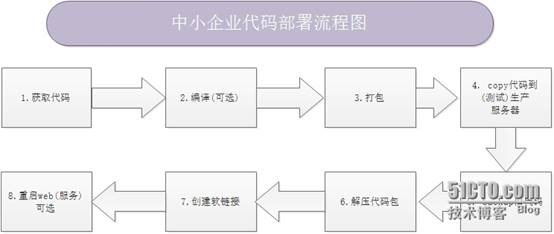
1. 获取代码可以通过svn或者git,通过制定项目的URL获取最新代码
2. java的项目我们是经过ant进行编译(编译服务器),(java项目可以通过ant或者maven进行编译)
PHP 的不需要进行编译。
将获取的代码进行打包 tar zcf
将打好的包copy到目标服务器上
备份目标机器上原有需要部署代码(可选)
在目标服务器上解压代码包
创建软链接,使用软链接的方式管理包的更新,代码更新之后只需要链接到最新的代码之上就可以了
路径如:web->/opt/project/xxx_2015-09-26-21-37-v1(这里也相当于取消了旧代码的软链接)
- 重启web (java)
测试就交给开发了,有些公司有测试平台,但是好在我们不负责测试
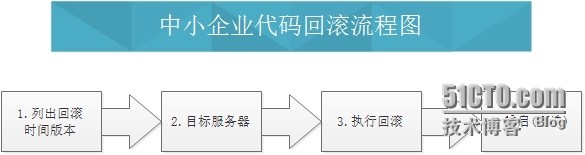
# 3.2 代码上线流程图
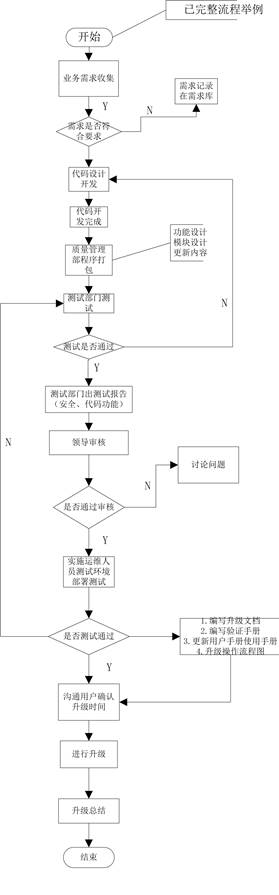
# 3.3 自动化代码上线流程图
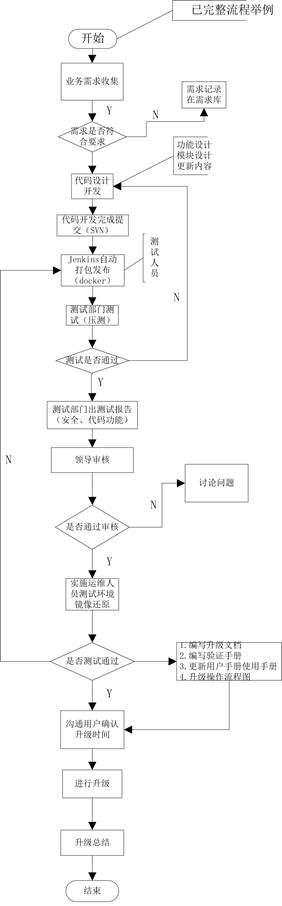
# 3.4 自动化构建流程图
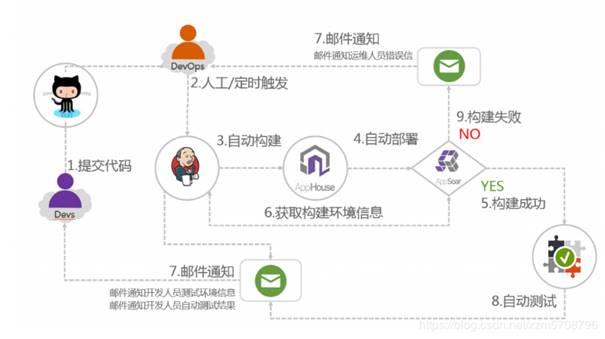
# 4. 服务器巡检
# 4.1 日常服务器运维部自我巡检:
(1)每日早8:00通过zabbix监控软件查看所有服务器总流量、单兵流量、CPU和内存使用情况、硬盘使用情况等运行是否正常。
(2)对异常单兵服务器进行查看CPU、内存占用率等进行详细分析和排查。
(3)对异常单兵进行所有服务进程检查,看是否正常,并进行排查。
(4)查看使用用户,是否有异常用户登录。如有异常用户登录,查看该用户下的文件,是否有木马、病毒或有威胁的文件,进行删除和维护。
(5)查看服务器系统是否需要打新的补丁,如需升级,进行升级。
(6)在服务器和本机上同时对网页的打开速度进行测试,登陆到系统上查看系统页面中程序运行是否正常。 是否正常。
(7)对公司五大系统接口进行打开测试查看是否正常。
测试内容:
集采平台打开测试;
便利店系统打开测试;
云仓储接口打开测试;
云管理接口打开测试;
云支付买买金接口打开测试。
# 4.2 周和月服务器运维部自我巡检:
通过查看监控周流量和月流量、服务器各项硬件使用情况查看等分析
(1)在管理工具中查看事件查看器中的应用、安全、系统、日志中的工作状态,是否有异常情况,如有进行清除和修复,每星期进行一次清除工作。
(2)每两个星期检查一次操作系统日志。
(3)每星期定时对服务器的网站程序文件进行备份。备份原则上采用数据库完全备份加日志备份策略、web前端增量备份;
1、备份数据存储策略:本机、异机、2个级别。
2、重要更新时间点前后必须做数据库备份或日志备份,特别是在做数据库表更新、应用程序更新。
3、每天检查所有数据库备份操作是否正确完成、异地传输是否正常完成,并填写检查表。
4、在异地备份数据准确存储后,可以将超过2周 以上的异机备份数据通过自动删除脚本进行删除,以便腾出存储空间。
(4)为保证服务器系统正常运行,每星期对系统盘C盘进行垃圾清理和维护。
(5)在数据库服务器、关键应用服务器上,只能有数据库DBA人员的帐号,开发人员需要介入时,填写开发人员使用数据库申请单向上级申请。
# 4.3 运维部自我巡检周和月工作总结:
对一个月内服务器系统的运行情况进行汇总,把解决的问题及不能解决的问题归纳总结并向上级领导提交,通过会议形式决定解决办法和执行方式来解决所面临的问题。
4.机房协助巡检:
机房每周会对机柜使用情况、流量峰值情况、机柜温度、湿度等进行巡检,每周发送到公司运维部,进行评估和查看
# 4.4 服务器硬件定期更换和清理:
针对所有服务器硬件清洁期限和更换如下:
1、每年进行服务器灰尘开盖清理,通过机房人员协助;
2、对于存储硬盘,期限为两年更换一次,保证硬盘的正常使用;
3、电源模块测试,若有欠压和损坏的进行彻底更换。