 rabbitmq
rabbitmq
# 1. 消息队列之 RabbitMQ
关于消息队列,从前年开始断断续续看了些资料,想写很久了,但一直没腾出空,近来分别碰到几个朋友聊这块的技术选型,是时候把这块的知识整理记录一下了。
市面上的消息队列产品有很多,比如老牌的 ActiveMQ、RabbitMQ ,目前我看最火的 Kafka ,还有 ZeroMQ ,去年底阿里巴巴捐赠给 Apache 的 RocketMQ ,连 redis 这样的 NoSQL 数据库也支持 MQ 功能。总之这块知名的产品就有十几种,就我自己的使用经验和兴趣只打算谈谈 RabbitMQ、Kafka 和 ActiveMQ ,本文先讲 RabbitMQ ,在此之前先看下消息队列的相关概念。
# 2. 什么叫消息队列
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
# 3. 为何用消息队列
从上面的描述中可以看出消息队列是一种应用间的异步协作机制,那什么时候需要使用 MQ 呢?
以常见的订单系统为例,用户点击【下单】按钮之后的业务逻辑可能包括:扣减库存、生成相应单据、发红包、发短信通知。在业务发展初期这些逻辑可能放在一起同步执行,随着业务的发展订单量增长,需要提升系统服务的性能,这时可以将一些不需要立即生效的操作拆分出来异步执行,比如发放红包、发短信通知等。这种场景下就可以用 MQ ,在下单的主流程(比如扣减库存、生成相应单据)完成之后发送一条消息到 MQ 让主流程快速完结,而由另外的单独线程拉取MQ的消息(或者由 MQ 推送消息),当发现 MQ 中有发红包或发短信之类的消息时,执行相应的业务逻辑。
以上是用于业务解耦的情况,其它常见场景包括最终一致性、广播、错峰流控等等。
# 4. RabbitMQ 特点
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
可靠性(Reliability) RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。
灵活的路由(Flexible Routing) 在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。
消息集群(Clustering) 多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。
高可用(Highly Available Queues) 队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。
多种协议(Multi-protocol) RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。
多语言客户端(Many Clients) RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。
管理界面(Management UI) RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。
跟踪机制(Tracing) 如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。
插件机制(Plugin System) RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
# 5. RabbitMQ 中的概念模型
# 消息模型
所有 MQ 产品从模型抽象上来说都是一样的过程: 消费者(consumer)订阅某个队列。生产者(producer)创建消息,然后发布到队列(queue)中,最后将消息发送到监听的消费者。
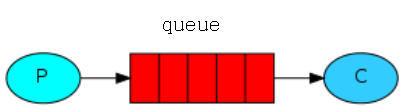
消息流
# RabbitMQ 基本概念
上面只是最简单抽象的描述,具体到 RabbitMQ 则有更详细的概念需要解释。上面介绍过 RabbitMQ 是 AMQP 协议的一个开源实现,所以其内部实际上也是 AMQP 中的基本概念:
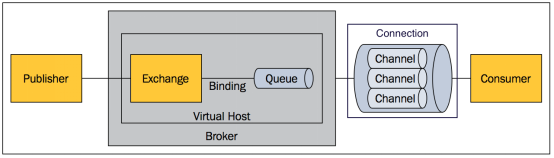
RabbitMQ 内部结构
Message 消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
Publisher 消息的生产者,也是一个向交换器发布消息的客户端应用程序。
Exchange 交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
Binding 绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
Queue 消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
Connection 网络连接,比如一个TCP连接。
Channel 信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内地虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
Consumer 消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
Virtual Host 虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMQ 默认的 vhost 是 / 。
Broker 表示消息队列服务器实体。
# AMQP 中的消息路由
AMQP 中消息的路由过程和 Java 开发者熟悉的 JMS 存在一些差别,AMQP 中增加了 Exchange 和 Binding 的角色。生产者把消息发布到 Exchange 上,消息最终到达队列并被消费者接收,而 Binding 决定交换器的消息应该发送到那个队列。
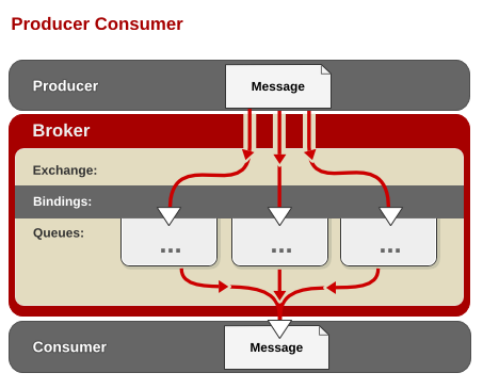
AMQP 的消息路由过程
# Exchange 类型
Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、fanout、topic、headers 。headers 匹配 AMQP 消息的 header 而不是路由键,此外 headers 交换器和 direct 交换器完全一致,但性能差很多,目前几乎用不到了,所以直接看另外三种类型:
- direct
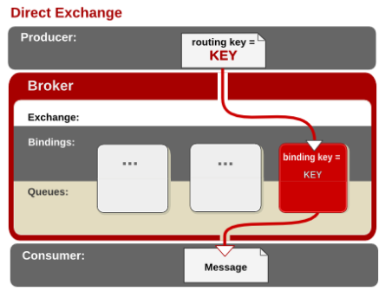
direct 交换器
消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器就将消息发到对应的队列中。路由键与队列名完全匹配,如果一个队列绑定到交换机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发“dog.puppy”,也不会转发“dog.guard”等等。它是完全匹配、单播的模式。
- fanout
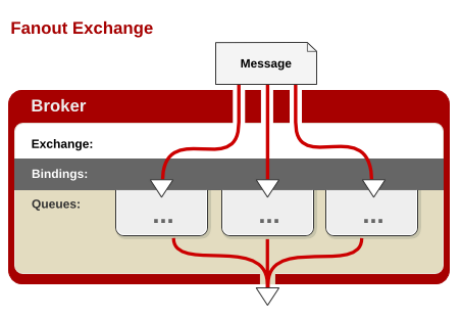
fanout 交换器
每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。fanout 交换器不处理路由键,只是简单的将队列绑定到交换器上,每个发送到交换器的消息都会被转发到与该交换器绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快的。
- topic
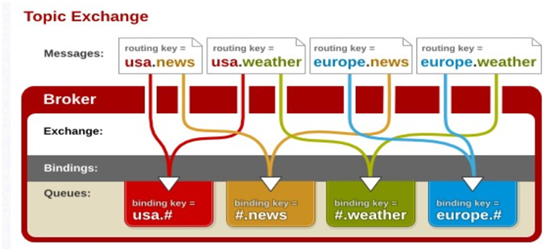
topic 交换器
topic 交换器通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号“*”。#匹配0**个或多个单词,*匹配不多不少一个单词。
# 6. RabbitMQ 安装
一般来说安装 RabbitMQ 之前要安装 Erlang ,可以去Erlang官网 (opens new window)下载。接着去RabbitMQ官网 (opens new window)下载安装包,之后解压缩即可。根据操作系统不同官网提供了相应的安装说明:Windows (opens new window)、Debian / Ubuntu (opens new window)、RPM-based Linux (opens new window)、Mac (opens new window)
如果是Mac 用户,个人推荐使用 HomeBrew 来安装,安装前要先更新 brew:
brew update
接着安装 rabbitmq 服务器:
brew install rabbitmq
这样 RabbitMQ 就安装好了,安装过程中会自动其所依赖的 Erlang 。
下载erlang
https://www.erlang-solutions.com/resources/download.html
wget https://packages.erlang-solutions.com/erlang-solutions-2.0-1.noarch.rpm
rpm -Uvh erlang-solutions-2.0-1.noarch.rpm
rpm --import https://packages.erlang-solutions.com/rpm/erlang_solutions.asc
yum install erlang -y
下载rabbitmq
https://www.rabbitmq.com/download.html
https://github.com/rabbitmq/rabbitmq-server/releases
vim /etc/profile.d/rabbit.sh
PATH=/opt/rabbitmq/sbin:$PATH
# 7. RabbitMQ 运行和管理
- 启动 启动很简单,找到安装后的 RabbitMQ 所在目录下的 sbin 目录,可以看到该目录下有6个以 rabbitmq 开头的可执行文件,直接执行 rabbitmq-server 即可,下面将 RabbitMQ 的安装位置以 . 代替,启动命令就是:
./sbin/rabbitmq-server
启动正常的话会看到一些启动过程信息和最后的 completed with 7 plugins,这也说明启动的时候默认加载了7个插件。
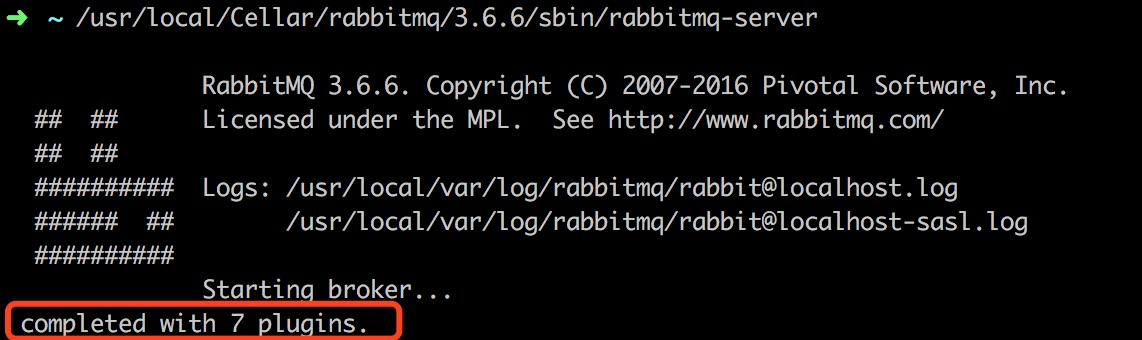
正常启动
- 后台启动 如果想让 RabbitMQ 以守护程序的方式在后台运行,可以在启动的时候加上 -detached 参数:
./sbin/rabbitmq-server -detached
- 查询服务器状态 sbin 目录下有个特别重要的文件叫 rabbitmqctl ,它提供了 RabbitMQ 管理需要的几乎一站式解决方案,绝大部分的运维命令它都可以提供。 查询 RabbitMQ 服务器的状态信息可以用参数 status :
./sbin/rabbitmqctl status
该命令将输出服务器的很多信息,比如 RabbitMQ 和 Erlang 的版本、OS 名称、内存等等
- 关闭 RabbitMQ 节点 我们知道 RabbitMQ 是用 Erlang 语言写的,在Erlang 中有两个概念:节点和应用程序。节点就是 Erlang 虚拟机的每个实例,而多个 Erlang 应用程序可以运行在同一个节点之上。节点之间可以进行本地通信(不管他们是不是运行在同一台服务器之上)。比如一个运行在节点A上的应用程序可以调用节点B上应用程序的方法,就好像调用本地函数一样。如果应用程序由于某些原因奔溃,Erlang 节点会自动尝试重启应用程序。 如果要关闭整个 RabbitMQ 节点可以用参数 stop :
./sbin/rabbitmqctl stop
它会和本地节点通信并指示其干净的关闭,也可以指定关闭不同的节点,包括远程节点,只需要传入参数 -n :
./sbin/rabbitmqctl -n rabbit@server.example.com stop
-n node 默认 node 名称是 rabbit@server ,如果你的主机名是 server.example.com (opens new window) ,那么 node 名称就是 rabbit@server.example.com (opens new window) 。
- 关闭 RabbitMQ 应用程序 如果只想关闭应用程序,同时保持 Erlang 节点运行则可以用 stop_app:
./sbin/rabbitmqctl stop_app
这个命令在后面要讲的集群模式中将会很有用。
- 启动 RabbitMQ 应用程序
./sbin/rabbitmqctl start_app
- 重置 RabbitMQ 节点
./sbin/rabbitmqctl reset
该命令将清除所有的队列。
- 查看已声明的队列
./sbin/rabbitmqctl list_queues
- 查看交换器
./sbin/rabbitmqctl list_exchanges
该命令还可以附加参数,比如列出交换器的名称、类型、是否持久化、是否自动删除:
./sbin/rabbitmqctl list_exchanges name type durable auto_delete
- 查看绑定
./sbin/rabbitmqctl list_bindings
- 启用web插件
rabbitmq-plugins enable rabbitmq_management
# 8. Java 客户端访问
RabbitMQ 支持多种语言访问,以 Java 为例看下一般使用 RabbitMQ 的步骤。
- maven工程的pom文件中添加依赖
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>4.1.0</version>
</dependency>
2
3
4
5
- 消息生产者
package org.study.rabbitmq;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
public class Producer {
public static void main(String[] args) throws IOException, TimeoutException {
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("guest");
factory.setPassword("guest");
//设置 RabbitMQ 地址
factory.setHost("localhost");
//建立到代理服务器到连接
Connection conn = factory.newConnection();
//获得信道
Channel channel = conn.createChannel();
//声明交换器
String exchangeName = "hello-exchange";
channel.exchangeDeclare(exchangeName, "direct", true);
String routingKey = "hola";
//发布消息
byte[] messageBodyBytes = "quit".getBytes();
channel.basicPublish(exchangeName, routingKey, null, messageBodyBytes);
channel.close();
conn.close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
- 消息消费者
package org.study.rabbitmq;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
public class Consumer {
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("guest");
factory.setPassword("guest");
factory.setHost("localhost");
//建立到代理服务器到连接
Connection conn = factory.newConnection();
//获得信道
final Channel channel = conn.createChannel();
//声明交换器
String exchangeName = "hello-exchange";
channel.exchangeDeclare(exchangeName, "direct", true);
//声明队列
String queueName = channel.queueDeclare().getQueue();
String routingKey = "hola";
//绑定队列,通过键 hola 将队列和交换器绑定起来
channel.queueBind(queueName, exchangeName, routingKey);
while(true) {
//消费消息
boolean autoAck = false;
String consumerTag = "";
channel.basicConsume(queueName, autoAck, consumerTag, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body) throws IOException {
String routingKey = envelope.getRoutingKey();
String contentType = properties.getContentType();
System.out.println("消费的路由键:" + routingKey);
System.out.println("消费的内容类型:" + contentType);
long deliveryTag = envelope.getDeliveryTag();
//确认消息
channel.basicAck(deliveryTag, false);
System.out.println("消费的消息体内容:");
String bodyStr = new String(body, "UTF-8");
System.out.println(bodyStr);
}
});
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
- 启动 RabbitMQ 服务器
./sbin/rabbitmq-server
运行 Consumer 先运行 Consumer ,这样当生产者发送消息的时候能在消费者后端看到消息记录。
运行 Producer 接着运行 Producer ,发布一条消息,在 Consumer 的控制台能看到接收的消息:
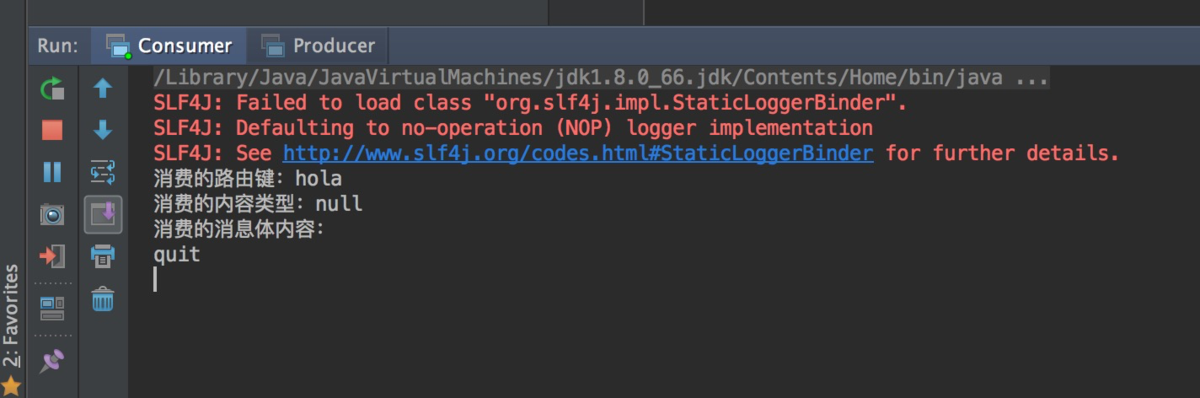
Consumer 控制台
# 9. RabbitMQ 集群
RabbitMQ 最优秀的功能之一就是内建集群,这个功能设计的目的是允许消费者和生产者在节点崩溃的情况下继续运行,以及通过添加更多的节点来线性扩展消息通信吞吐量。RabbitMQ 内部利用 Erlang 提供的分布式通信框架 OTP 来满足上述需求,使客户端在失去一个 RabbitMQ 节点连接的情况下,还是能够重新连接到集群中的任何其他节点继续生产、消费消息。
# RabbitMQ 集群中的一些概念
RabbitMQ 会始终记录以下四种类型的内部元数据:
队列元数据 包括队列名称和它们的属性,比如是否可持久化,是否自动删除
交换器元数据 交换器名称、类型、属性
绑定元数据 内部是一张表格记录如何将消息路由到队列
vhost 元数据 为 vhost 内部的队列、交换器、绑定提供命名空间和安全属性
在单一节点中,RabbitMQ 会将所有这些信息存储在内存中,同时将标记为可持久化的队列、交换器、绑定存储到硬盘上。存到硬盘上可以确保队列和交换器在节点重启后能够重建。而在集群模式下同样也提供两种选择:存到硬盘上(独立节点的默认设置),存在内存中。
如果在集群中创建队列,集群只会在单个节点而不是所有节点上创建完整的队列信息(元数据、状态、内容)。结果是只有队列的所有者节点知道有关队列的所有信息,因此当集群节点崩溃时,该节点的队列和绑定就消失了,并且任何匹配该队列的绑定的新消息也丢失了。还好RabbitMQ 2.6.0之后提供了镜像队列以避免集群节点故障导致的队列内容不可用。
RabbitMQ 集群中可以共享 user、vhost、exchange等,所有的数据和状态都是必须在所有节点上复制的,例外就是上面所说的消息队列。RabbitMQ 节点可以动态的加入到集群中。
当在集群中声明队列、交换器、绑定的时候,这些操作会直到所有集群节点都成功提交元数据变更后才返回。集群中有内存节点和磁盘节点两种类型,内存节点虽然不写入磁盘,但是它的执行比磁盘节点要好。内存节点可以提供出色的性能,磁盘节点能保障配置信息在节点重启后仍然可用,那集群中如何平衡这两者呢?
RabbitMQ 只要求集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入火离开集群时,它们必须要将该变更通知到至少一个磁盘节点。如果只有一个磁盘节点,刚好又是该节点崩溃了,那么集群可以继续路由消息,但不能创建队列、创建交换器、创建绑定、添加用户、更改权限、添加或删除集群节点。换句话说集群中的唯一磁盘节点崩溃的话,集群仍然可以运行,但知道该节点恢复,否则无法更改任何东西。
# 10. 操作
#新增用户admin,密码为admins-1
rabbitmqctl add_user admin admins-1
#更改密码
rabbitmqctl change_password admin 123456
#查看用户列表
rabbitmqctl list_users
#赋予用户全部操作权限
rabbitmqctl set_permissions -p / admin "." "." ".*"
#将admin加入到管理员组
rabbitmqctl set_user_tags admin administrator
#查看用户的权限
rabbitmqctl list_user_permissions admin
#(最后操作)由于RabbitMQ默认的账号用户名和密码都是guest。为了安全起见, 先删掉默认用户
rabbitmqctl delete_user guest
# 11. 开机脚本
cat <<'EOF' >> /usr/lib/systemd/system/rabbitmq-server.service
[Unit]
Description=RabbitMQ broker
After=syslog.target network.target
[Service]
#Type=notify
User=root
Group=root
WorkingDirectory=/opt/rabbitmq
ExecStart=/opt/rabbitmq/sbin/rabbitmq-server
ExecStop=/opt/rabbitmq/sbin/rabbitmqctl stop
[Install]
WantedBy=multi-user.target
EOF
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#!/bin/sh
#
# rabbitmq-server RabbitMQ broker
#
# chkconfig: - 80 05
# description: Enable AMQP service provided by RabbitMQ
#
### BEGIN INIT INFO
# Provides: rabbitmq-server
# Required-Start: $remote_fs $network
# Required-Stop: $remote_fs $network
# Description: RabbitMQ broker
# Short-Description: Enable AMQP service provided by RabbitMQ broker
### END INIT INFO
# Source function library.
. /etc/init.d/functions
export HOME=/root
PATH=/sbin:/usr/sbin:/bin:/usr/bin
NAME=rabbitmq-server
#DAEMON=/usr/sbin/${NAME}
#CONTROL=/usr/sbin/rabbitmqctl
DAEMON=/home/software/rabbitmq/sbin/${NAME}
CONTROL=/home/software/rabbitmq/sbin/rabbitmqctl
DESC=rabbitmq-server
USER=admin
ROTATE_SUFFIX=
INIT_LOG_DIR=/var/log/rabbitmq
PID_FILE=/var/run/rabbitmq/pid
START_PROG="daemon"
LOCK_FILE=/var/lock/subsys/$NAME
test -x $DAEMON || exit 0
test -x $CONTROL || exit 0
RETVAL=0
set -e
[ -f /etc/default/${NAME} ] && . /etc/default/${NAME}
ensure_pid_dir () {
PID_DIR=`dirname ${PID_FILE}`
if [ ! -d ${PID_DIR} ] ; then
mkdir -p ${PID_DIR}
chown -R ${USER}:${USER} ${PID_DIR}
chmod 755 ${PID_DIR}
fi
}
remove_pid () {
rm -f ${PID_FILE}
rmdir `dirname ${PID_FILE}` || :
}
start_rabbitmq () {
status_rabbitmq quiet
if [ $RETVAL = 0 ] ; then
echo RabbitMQ is currently running
else
RETVAL=0
ensure_pid_dir
set +e
RABBITMQ_PID_FILE=$PID_FILE $START_PROG $DAEMON
> "${INIT_LOG_DIR}/startup_log"
2> "${INIT_LOG_DIR}/startup_err"
0<&- &
$CONTROL wait $PID_FILE >/dev/null 2>&1
RETVAL=$?
set -e
case "$RETVAL" in
0)
echo SUCCESS
if [ -n "$LOCK_FILE" ] ; then
touch $LOCK_FILE
fi
;;
*)
remove_pid
echo FAILED - check ${INIT_LOG_DIR}/startup_{log, _err}
RETVAL=1
;;
esac
fi
}
stop_rabbitmq () {
status_rabbitmq quiet
if [ $RETVAL = 0 ] ; then
set +e
$CONTROL stop ${PID_FILE} > ${INIT_LOG_DIR}/shutdown_log 2> ${INIT_LOG_DIR}/shutdown_err
RETVAL=$?
set -e
if [ $RETVAL = 0 ] ; then
remove_pid
if [ -n "$LOCK_FILE" ] ; then
rm -f $LOCK_FILE
fi
else
echo FAILED - check ${INIT_LOG_DIR}/shutdown_log, _err
fi
else
echo RabbitMQ is not running
RETVAL=0
fi
}
status_rabbitmq() {
set +e
if [ "$1" != "quiet" ] ; then
$CONTROL status 2>&1
else
$CONTROL status > /dev/null 2>&1
fi
if [ $? != 0 ] ; then
RETVAL=3
fi
set -e
}
rotate_logs_rabbitmq() {
set +e
$CONTROL rotate_logs ${ROTATE_SUFFIX}
if [ $? != 0 ] ; then
RETVAL=1
fi
set -e
}
restart_running_rabbitmq () {
status_rabbitmq quiet
if [ $RETVAL = 0 ] ; then
restart_rabbitmq
else
echo RabbitMQ is not runnning
RETVAL=0
fi
}
restart_rabbitmq() {
stop_rabbitmq
start_rabbitmq
}
case "$1" in
start)
echo -n "Starting $DESC: "
start_rabbitmq
echo "$NAME."
;;
stop)
echo -n "Stopping $DESC: "
stop_rabbitmq
echo "$NAME."
;;
status)
status_rabbitmq
;;
rotate-logs)
echo -n "Rotating log files for $DESC: "
rotate_logs_rabbitmq
;;
force-reload|reload|restart)
echo -n "Restarting $DESC: "
restart_rabbitmq
echo "$NAME."
;;
try-restart)
echo -n "Restarting $DESC: "
restart_running_rabbitmq
echo "$NAME."
;;
*)
echo "Usage: $0 {start|stop|status|
rotate-logs|restart|condrestart|
try-restart|reload|force-reload}" >&2
RETVAL=1
;;
esac
exit $RETVAL
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
# RabbitMQ 高可用集群搭建
# 1. 集群简介
# 1.1 集群架构
当单台 RabbitMQ 服务器的处理消息的能力达到瓶颈时,此时可以通过 RabbitMQ 集群来进行扩展,从而达到提升吞吐量的目的。RabbitMQ 集群是一个或多个节点的逻辑分组,集群中的每个节点都是对等的,每个节点共享所有的用户,虚拟主机,队列,交换器,绑定关系,运行时参数和其他分布式状态等信息。一个高可用,负载均衡的 RabbitMQ 集群架构应类似下图: 这里对上面的集群架构做一下解释说明:
首先一个基本的 RabbitMQ 集群不是高可用的,虽然集群共享队列,但在默认情况下,消息只会被路由到某一个节点的符合条件的队列上,并不会同步到其他节点的相同队列上。假设消息路由到 node1 的 my-queue 队列上,但是 node1 突然宕机了,那么消息就会丢失,想要解决这个问题,需要开启队列镜像,将集群中的队列彼此之间进行镜像,此时消息就会被拷贝到处于同一个镜像分组中的所有队列上。
其次 RabbitMQ 集群本身并没有提供负载均衡的功能,也就是说对于一个三节点的集群,每个节点的负载可能都是不相同的,想要解决这个问题可以通过硬件负载均衡或者软件负载均衡的方式,这里我们选择使用 HAProxy 来进行负载均衡,当然也可以使用其他负载均衡中间件,如LVS等。HAProxy 同时支持四层和七层负载均衡,并基于单一进程的事件驱动模型,因此它可以支持非常高的井发连接数。
接着假设我们只采用一台 HAProxy ,那么它就存在明显的单点故障的问题,所以至少需要两台 HAProxy ,同时这两台 HAProxy 之间需要能够自动进行故障转移,通常的解决方案就是 KeepAlived 。KeepAlived 采用 VRRP (Virtual Router Redundancy Protocol,虚拟路由冗余协议) 来解决单点失效的问题,它通常由一组一备两个节点组成,同一时间内只有主节点会提供对外服务,并同时提供一个虚拟的 IP 地址 (Virtual Internet Protocol Address ,简称 VIP) 。 如果主节点故障,那么备份节点会自动接管 VIP 并成为新的主节点 ,直到原有的主节点恢复。
最后,任何想要连接到 RabbitMQ 集群的客户端只需要连接到虚拟 IP,而不必关心集群是何种架构,示例如下:
ConnectionFactory factory = new ConnectionFactory(); // 假设虚拟ip为 192.168.0.200 factory.setHost("192.168.0.200");
# 1.2 部署情况
下面我们开始进行搭建,这里我使用三台主机,主机名分别为 rabbit-node2, rabbit-node3 和 rabbit3 ,其功能分配如下:
主机名 IP地址 部署服务 操作系统 配置 rabbit-node1 192.168.0.12 RabbitMQ + HAProxy + KeepAlived CentOS 7.6 4核8G rabbit-node2 192.168.0.14 RabbitMQ + HAProxy + KeepAlived CentOS 7.6 4核8G rabbit-node3 192.168.0.15 RabbitMQ CentOS 7.6 4核8G
以上三台主机上我均已安装好了 RabbitMQ ,关于 RabbitMQ 的安装步骤可以参考:《RabbitMQ单机环境搭建》
# 2. RabbitMQ 集群搭建
# 2.1 初始化环境
分别修改主机名
hostnamectl set-hostname rabbit-node1 修改每台机器的 /etc/hosts 文件
cat >> /etc/hosts <<EOF 192.168.0.12 rabbit-node1 192.168.0.14 rabbit-node2 192.168.0.15 rabbit-node3 EOF
重启虚拟机便于系统识别hosts
# 重启网络
systemctl restart network setenforce 0
# 重启
init 6
# 2.2 配置 Erlang Cookie
将 rabbit-node1 上的 .erlang.cookie 文件拷贝到其他两台主机上。该 cookie 文件相当于密钥令牌,集群中的 RabbitMQ 节点需要通过交换密钥令牌以获得相互认证,因此处于同一集群的所有节点需要具有相同的密钥令牌,否则在搭建过程中会出现 Authentication Fail 错误。
RabbitMQ 服务启动时,erlang VM 会自动创建该 cookie 文件,默认的存储路径为 /var/lib/rabbitmq/.erlang.cookie 或 $HOME/.erlang.cookie,该文件是一个隐藏文件,需要使用 ls -al 命令查看。(拷贝.cookie时,各节点都必须停止MQ服务):
# 停止所有服务,构建Erlang的集群环境
systemctl stop rabbitmq-server
scp /var/lib/rabbitmq/.erlang.cookie root@rabbit-node2:/var/lib/rabbitmq/ scp /var/lib/rabbitmq/.erlang.cookie root@rabbit-node3:/var/lib/rabbitmq/
由于你可能在三台主机上使用不同的账户进行操作,为避免后面出现权限不足的问题,这里建议将 cookie 文件原来的 400 权限改为 600,命令如下:
chmod 600 /var/lib/rabbitmq/.erlang.cookie
注:cookie 中的内容就是一行随机字符串,可以使用 cat 命令查看。
# 2.3 启动服务
在三台主机上均执行以下命令,启动 RabbitMQ 服务:
systemctl start rabbitmq-server
开通 EPMD 端口
epmd进程使用的端口。用于RabbitMQ节点和CLI工具的端点发现服务。
# 开启防火墙 4369 端口
firewall-cmd --zone=public --add-port=4369/tcp --permanent
# 重启
systemctl restart firewalld.service
# 2.4 集群搭建
RabbitMQ 集群的搭建需要选择其中任意一个节点为基准,将其它节点逐步加入。这里我们以 rabbit-node1 为基准节点,将 rabbit-node2 和 rabbit-node3 加入集群。在 rabbit-node2 和rabbit-node3 上执行以下命令:
1.停止服务
rabbitmqctl stop_app
2.重置状态
rabbitmqctl reset
3.节点加入, 在一个node加入cluster之前,必须先停止该node的rabbitmq应用,即先执行stop_app
rabbit-node2加入node1, rabbit-node3加入node2
rabbitmqctl join_cluster rabbit@rabbit-node1
4.启动服务
rabbitmqctl start_app
join_cluster 命令有一个可选的参数 --ram ,该参数代表新加入的节点是内存节点,默认是磁盘节点。如果是内存节点,则所有的队列、交换器、绑定关系、用户、访问权限和 vhost 的元数据都将存储在内存中,如果是磁盘节点,则存储在磁盘中。内存节点可以有更高的性能,但其重启后所有配置信息都会丢失,因此RabbitMQ 要求在集群中至少有一个磁盘节点,其他节点可以是内存节点。当内存节点离开集群时,它可以将变更通知到至少一个磁盘节点;然后在其重启时,再连接到磁盘节点上获取元数据信息。除非是将 RabbitMQ 用于 RPC 这种需要超低延迟的场景,否则在大多数情况下,RabbitMQ 的性能都是够用的,可以采用默认的磁盘节点的形式。这里为了演示, rabbit-node3 我就设置为内存节点。
另外,如果节点以磁盘节点的形式加入,则需要先使用 reset 命令进行重置,然后才能加入现有群集,重置节点会删除该节点上存在的所有的历史资源和数据。采用内存节点的形式加入时可以略过 reset 这一步,因为内存上的数据本身就不是持久化的。
# 2.5 查看集群状态
2.5.1 命令行查看 在 rabbit-node3 和 3 上执行以上命令后,集群就已经搭建成功,此时可以在任意节点上使用 rabbitmqctl cluster_status 命令查看集群状态,输出如下:
[root@rabbit-node1 keepalived]# rabbitmqctl cluster_status Cluster status of node rabbit@rabbit-node1 ... [{nodes,[{disc,['rabbit@rabbit-node1','rabbit@rabbit-node2', 'rabbit@rabbit-node3']}]}, {running_nodes,['rabbit@rabbit-node3','rabbit@rabbit-node2', 'rabbit@rabbit-node1']}, {cluster_name,<<"rabbit@rabbit-node1">>}, {partitions,[]}, {alarms,[{'rabbit@rabbit-node3',[]}, {'rabbit@rabbit-node2',[]}, {'rabbit@rabbit-node1',[]}]}]
可以看到 nodes 下显示了全部节点的信息,其中 rabbit-node2 和 rabbit3 上的节点都是 disc 类型,即磁盘节点;而 rabbit-node3 上的节点为 ram,即内存节点。此时代表集群已经搭建成功,默认的 cluster_name 名字为 rabbit@rabbit-node1,如果你想进行修改,可以使用以下命令:
rabbitmqctl set_cluster_name my_rabbitmq_cluster
2.5.2 UI 界面查看 除了可以使用命令行外,还可以使用打开任意节点的 UI 界面进行查看,情况如下:
# 2.6 配置镜像队列
2.6.1 开启镜像队列 这里我们为所有队列开启镜像配置,其语法如下:
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
2.6.2 复制系数 在上面我们指定了 ha-mode 的值为 all ,代表消息会被同步到所有节点的相同队列中。这里我们之所以这样配置,因为我们本身只有三个节点,因此复制操作的性能开销比较小。如果你的集群有很多节点,那么此时复制的性能开销就比较大,此时需要选择合适的复制系数。通常可以遵循过半写原则,即对于一个节点数为 n 的集群,只需要同步到 n/2+1 个节点上即可。此时需要同时修改镜像策略为 exactly,并指定复制系数 ha-params,示例命令如下:
rabbitmqctl set_policy ha-two "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
除此之外,RabbitMQ 还支持使用正则表达式来过滤需要进行镜像操作的队列,示例如下:
rabbitmqctl set_policy ha-all "^ha." '{"ha-mode":"all"}'
此时只会对 ha 开头的队列进行镜像。更多镜像队列的配置说明,可以参考官方文档:Highly Available (Mirrored) Queues
2.6.3 查看镜像状态 配置完成后,可以通过 Web UI 界面查看任意队列的镜像状态,情况如下:
# 2.7 集群的关闭与重启
没有一个直接的命令可以关闭整个集群,需要逐一进行关闭。但是需要保证在重启时,最后关闭的节点最先被启动。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的那个节点启动,默认进行 10 次连接尝试,超时时间为 30 秒,如果依然没有等到,则该节点启动失败。
这带来的一个问题是,假设在一个三节点的集群当中,关闭的顺序为 node1,node2,node3,如果 node1 因为故障暂时没法恢复,此时 node2 和 node3 就无法启动。想要解决这个问题,可以先将 node1 节点进行剔除,命令如下:
rabbitmqctl forget_cluster_node rabbit@node1 --offline
此时需要加上 -offline 参数,它允许节点在自身没有启动的情况下将其他节点剔除。
# 2.8 解除集群
重置当前节点
1.停止服务
rabbitmqctl stop_app
2.重置集群状态
rabbitmqctl reset
3.重启服务
rabbitmqctl start_app
重新加入集群
1.停止服务
rabbitmqctl stop_app
2.重置状态
rabbitmqctl reset
3.节点加入
rabbitmqctl join_cluster rabbit@rabbit-node1
4.重启服务
rabbitmqctl start_app
完成后重新检查 RabbitMQ 集群状态
rabbitmqctl cluster_status
除了在当前节点重置集群外,还可在集群其他正常节点将节点踢出集群
rabbitmqctl forget_cluster_node rabbit@rabbit-node3
# 2.9 变更节点类型
我们可以将节点的类型从RAM更改为Disk,反之亦然。假设我们想要反转rabbit@rabbit-node2和rabbit@rabbit-node1的类型,将前者从RAM节点转换为磁盘节点,而后者从磁盘节点转换为RAM节点。为此,我们可以使用change_cluster_node_type命令。必须首先停止节点。
1.停止服务
rabbitmqctl stop_app
2.变更类型 ram disc
rabbitmqctl change_cluster_node_type disc
3.重启服务
rabbitmqctl start_app
2.10 清除 RabbitMQ 节点配置
如果遇到不能正常退出直接kill进程
systemctl stop rabbitmq-server
查看进程
ps aux|grep rabbitmq
清楚节点rabbitmq配置
rm -rf /var/lib/rabbitmq/mnesia
# 3. HAProxy 环境搭建
yum 源安装目前版本比较低,采用源码安装方式。
# 3.1 下载
HAProxy 官方下载地址为:www.haproxy.org/#down ,如果这个网站无法访问,也可以从 src.fedoraproject.org/repo/pkgs/h… 上进行下载。这里我下载的是 2.x 的版本,下载后进行解压:
tar -zxvf haproxy-2.1.8.tar.gz
# 3.2 编译
进入解压后根目录,执行下面的编译命令:
make TARGET=linux-glibc PREFIX=/usr/local/haproxy-2.1.8 make install PREFIX=/usr/local/haproxy-2.1.8
# 3.3 配置环境变量
配置环境变量:
vim /etc/profile
export HAPROXY_HOME=/usr/local/haproxy-2.1.8 export PATH=$PATH:$HAPROXY_HOME/sbin
使得配置的环境变量立即生效:
source /etc/profile
检查安装是否成功:
[root@rabbit-node1 haproxy-2.1.8]# haproxy -v HA-Proxy version 2.1.8 2020/07/31 - https://haproxy.org/ Status: stable branch - will stop receiving fixes around Q1 2021. Known bugs: http://www.haproxy.org/bugs/bugs-2.1.8.html Running on: Linux 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64
# 3.4 负载均衡配置
新建配置文件 haproxy.cfg,这里我新建的位置为:/etc/haproxy/haproxy.cfg。
创建目录
mkdir /etc/haproxy
编辑文件内容
vim /etc/haproxy/haproxy.cfg
文件内容如下:
全局配置
global
日志输出配置、所有日志都记录在本机,通过 local0 进行输出
log 127.0.0.1 local0 info
最大连接数
maxconn 4096
改变当前的工作目录
chroot /usr/local/haproxy-2.1.8
以指定的 UID 运行 haproxy 进程
uid 99
以指定的 GID 运行 haproxy 进程
gid 99
以守护进行的方式运行
daemon
当前进程的 pid 文件存放位置
pidfile /usr/local/haproxy-2.1.8/haproxy.pid
默认配置
defaults
应用全局的日志配置
log global
使用4层代理模式,7层代理模式则为"http"
mode tcp
日志类别
option tcplog
不记录健康检查的日志信息
option dontlognull
3次失败则认为服务不可用
retries 3
每个进程可用的最大连接数
maxconn 2000
连接超时
timeout connect 5s
客户端超时
timeout client 120s
服务端超时
timeout server 120s
绑定配置
listen rabbitmq_cluster bind :5671
配置TCP模式
mode tcp
采用加权轮询的机制进行负载均衡
balance roundrobin
RabbitMQ 集群节点配置
server mq-node1 rabbit-node1:5672 check inter 5000 rise 2 fall 3 weight 1 server mq-node2 rabbit-node2:5672 check inter 5000 rise 2 fall 3 weight 1 server mq-node3 rabbit-node3:5672 check inter 5000 rise 2 fall 3 weight 1
配置监控页面
listen monitor bind :8100 mode http option httplog stats enable stats uri /stats stats refresh 5s
负载均衡的主要配置在 listen rabbitmq_cluster 下,这里指定负载均衡的方式为加权轮询,同时定义好健康检查机制:
server node1 rabbit-node1:5672 check inter 5000 rise 2 fall 3 weight 1
以上配置代表对地址为 rabbit-node1:5672 的 node1 节点每隔 5 秒进行一次健康检查,如果连续两次的检查结果都是正常,则认为该节点可用,此时可以将客户端的请求轮询到该节点上;如果连续 3 次的检查结果都不正常,则认为该节点不可用。weight 用于指定节点在轮询过程中的权重。
# 3.5 启动服务
以上搭建步骤在 rabbit-node1 和 rabbit-node2 上完全相同,搭建完成使用以下命令启动服务:
启动
haproxy -f /etc/haproxy/haproxy.cfg
查看运行
ps aux|grep haproxy
停止 没有killall命令, 安装yum -y install psmisc
killall haproxy
开启监控页面访问端口
firewall-cmd --zone=public --add-port=8100/tcp --permanent systemctl restart firewalld.service
启动后可以在监控页面进行查看,端口为设置的 8100,完整地址为:http://rabbit-node1:8100/stats ,页面情况如下:
所有节点都为绿色,代表节点健康。此时证明 HAProxy 搭建成功,并已经对 RabbitMQ 集群进行监控。
# 4. Keepalived 环境搭建
接着就可以搭建 Keepalived 来解决 HAProxy 故障转移的问题。这里我在 rabbit-node1 和 rabbit-node2上安装 KeepAlived ,两台主机上的搭建的步骤完全相同,只是部分配置略有不同,具体如下:
环境说明 Name IP Addr Service Name Descprition VIP 192.168.0.200 虚拟 IP MASTER 192.168.0.12 rabbit-node1 主服务器 IP BACKUP 192.168.0.14 rabbit-node2 备服务器 IP
# 4.1 安装
Keepalived 可以使用 yum 直接安装,在 MASTER 服务器和 BACKUP 服务器执行:
yum -y install keepalived
# 4.2 配置 MASTER 和 BACKUP
确认网卡 [root@rabbit-node1 ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether fa:16:3e:52:87:80 brd ff:ff:ff:ff:ff:ff inet 192.168.0.12/24 brd 192.168.0.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever inet 192.168.0.200/32 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::f816:3eff:fe52:8780/64 scope link valid_lft forever preferred_lft forever [root@rabbit-node1 ~]#
本例使用 eth0 这块网卡。
vim /etc/keepalived/keepalived.conf
MASTER 节点配置 完整配置如下:
global_defs {
路由id,主备节点不能相同
router_id node1
notification_email {
email 接收方
acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc }
email 发送方
notification_email_from Alexandre.Cassen@firewall.loc
邮件服务器, smtp 协议
smtp_server 192.168.200.1 smtp_connect_timeout 30
vrrp_skip_check_adv_addr
使用 unicast_src_ip 需要注释 vrrp_strict,而且也可以进行 ping 测试
#vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 }
自定义监控脚本
vrrp_script chk_haproxy {
脚本位置
script "/etc/keepalived/haproxy_check.sh"
脚本执行的时间间隔
interval 5 weight 10 }
vrrp_instance VI_1 {
Keepalived的角色,MASTER 表示主节点,BACKUP 表示备份节点
state MASTER
指定监测的网卡,可以使用 ifconfig 进行查看
interface eth0
虚拟路由的id,主备节点需要设置为相同
virtual_router_id 51
优先级,主节点的优先级需要设置比备份节点高
priority 100
设置主备之间的检查时间,单位为秒
advert_int 1
如果两节点的上联交换机禁用了组播,则采用 vrrp 单播通告的方式
unicast_src_ip 192.168.0.12 unicast_peer { 192.168.0.14 }
定义验证类型和密码
authentication { auth_type PASS auth_pass 123456 }
调用上面自定义的监控脚本
track_script { chk_haproxy }
virtual_ipaddress { # 虚拟IP地址,可以设置多个 192.168.0.200 } }
备份节点的配置与主节点基本相同,但是需要修改其 state 为 BACKUP;同时其优先级 priority 需要比主节点低。
BACKUP 节点配置 完整配置如下:
global_defs {
路由id,主备节点不能相同
router_id node2
notification_email {
email 接收方
acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc }
email 发送方
notification_email_from Alexandre.Cassen@firewall.loc
邮件服务器, smtp 协议
smtp_server 192.168.200.1 smtp_connect_timeout 30
vrrp_skip_check_adv_addr
使用 unicast_src_ip 需要注释 vrrp_strict,而且也可以进行 ping 测试
#vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 }
vrrp_script chk_haproxy { script "/etc/keepalived/haproxy_check.sh" interval 5 weight 10 }
vrrp_instance VI_1 {
BACKUP 表示备份节点
state BACKUP
指定监测的网卡
interface eth0
虚拟路由的id,主备节点需要设置为相同
virtual_router_id 51
优先级,备份节点要比主节点低
priority 50
advert_int 1
如果两节点的上联交换机禁用了组播,则采用 vrrp 单播通告的方式
unicast_src_ip 192.168.0.14 unicast_peer { 192.168.0.12 }
authentication { auth_type PASS auth_pass 123456 }
track_script { chk_haproxy }
virtual_ipaddress { 192.168.0.200 } }
注意以下几点
state 角色为 BACKUP interface 为网卡的 ID,要根据机器确认 virtual_route_id 要与 MASTER 一致,默认为 51 priority 要比 MASTER 小 unicast_src_ip 要设置正确,组播地址设置之后,要注释 vrrp_strict 选项
# 4.3 配置 HAProxy 检查
以上配置定义了 Keepalived 的 MASTER 节点和 BACKUP 节点,并设置对外提供服务的虚拟 IP 为 192.168.0.200。此外最主要的是定义了通过 haproxy_check.sh 来对 HAProxy 进行监控,这个脚本需要我们自行创建,内容如下:
vim /etc/keepalived/haproxy_check.sh
#!/bin/bash
判断haproxy是否已经启动
if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then #如果没有启动,则启动 haproxy -f /etc/haproxy/haproxy.cfg fi
#睡眠3秒以便haproxy完全启动 sleep 3
#如果haproxy还是没有启动,此时需要将本机的keepalived服务停掉,以便让VIP自动漂移到另外一台haproxy if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then systemctl stop keepalived fi
创建后为其赋予执行权限
chmod +x /etc/keepalived/haproxy_check.sh
这个脚本主要用于判断 HAProxy 服务是否正常,如果不正常且无法启动,此时就需要将本机 Keepalived 关闭,从而让虚拟 IP 漂移到备份节点。
# 4.4 配置并启动服务
配置 IP 转发,需要修改配置文件 /etc/sysctl.conf,默认只有 root 可以修改,分别在 MASTER 和 BACKUP上修改。
切换用户
su -root
文件配置
echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.conf
生效
sysctl -p rabbit-node1 和 rabbit-node2 上启动 KeepAlived 服务,命令如下:
systemctl start keepalived
设置开机自动启
systemctl enable keepalived
启动后此时 rabbit-node1 为主节点,可以在 rabbit-node1 上使用 ip a 命令查看到虚拟 IP 的情况:
此时只有 rabbit-node1 上是存在虚拟 IP 的,而 rabbit-node2 上是没有的。
漂移规则如下:
默认使用 MASTER 服务器(192.168.0.12),虚拟 IP 为 192.168.0.200,此时 MASTER 服务器会有 2 个IP。 当 MASTER 出问题时,IP 会漂移到 BACKUP 服务器(192.168.0.14),此时 BACKUP 服务器会有 2 个IP。 当 MASTER 重新启动后,虚拟 IP 又会漂移回 MASTER 服务器。
# 4.5 验证故障转移
这里我们验证一下故障转移,因为按照我们上面的检测脚本,如果 HAProxy 已经停止且无法重启时 KeepAlived 服务就会停止,这里我们直接使用以下工具进行验证。
安装 tcpdump 包
yum -y install tcpdump
在 MASTER 服务器上执行
[root@rabbit-node1 ~]# tcpdump -i eth0 vrrp -n tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes 23:42:48.521201 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 23:42:49.522332 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 23:42:50.523458 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 23:42:51.524597 IP 192.168.0.12 > 192.168.0.14: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 ... ...
这表明 MASTER 在向 BACKUP 广播,MASTER 在线。此时虚拟 IP 时挂在 MASTER 上的,如果想退出, 按 Ctrl+C。
如果 MASTER 停止 keepalived,虚拟 IP 会漂移到 BACKUP 服务器上。 我们可以测试一下:
首先,停止 MASTER 的 keepalived
systemctl stop keepalived
然后,在 MASTER 服务器上查看 VRRP 服务
[root@rabbit-node1 ~]# tcpdump -i eth0 vrrp -n tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes 23:44:19.297025 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20 23:44:20.297257 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20 23:44:21.297652 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20 23:44:22.297348 IP 192.168.0.14 > 192.168.0.12: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20 ... ...
这表明 MASTER 收到 BACKUP 的广播,此时虚拟 IP 时挂在 BACKUP 服务器上。
此时再次使用 ip a 分别查看,可以发现 MASTER 上的 VIP 已经漂移到 BACKUP 上,情况如下:
再次重启 MASTER 服务器,会发现 VIP 又重新漂移回 MASTER 服务器。
此时对外服务的 VIP 依然可用,代表已经成功地进行了故障转移。至此集群已经搭建成功,任何需要发送或者接受消息的客户端服务只需要连接到该 VIP 即可,示例如下:
ConnectionFactory factory = new ConnectionFactory(); factory.setHost("192.168.0.200");
# 4.6 配置日志
注意
此配置为可选步骤。
keepalived 默认将日志输出到系统日志/var/log/messages中,因为系统日志很多,查询问题时相对麻烦。
我们可以将 keepalived 的日志单独拿出来,这需要修改日志输出路径。
修改 Keepalived 配置
vim /etc/sysconfig/keepalived
更改如下:
Options for keepalived. See `keepalived --help' output and keepalived(8) and
keepalived.conf(5) man pages for a list of all options. Here are the most
common ones :
#
--vrrp -P Only run with VRRP subsystem.
--check -C Only run with Health-checker subsystem.
--dont-release-vrrp -V Dont remove VRRP VIPs & VROUTEs on daemon stop.
--dont-release-ipvs -I Dont remove IPVS topology on daemon stop.
--dump-conf -d Dump the configuration data.
--log-detail -D Detailed log messages.
--log-facility -S 0-7 Set local syslog facility (default=LOG_DAEMON)
#
KEEPALIVED_OPTIONS="-D -d -S 0"
把 KEEPALIVED_OPTIONS=”-D” 修改为 KEEPALIVED_OPTIONS=”-D -d -S 0”,其中 -S 指定 syslog 的 facility
修改 /etc/rsyslog.conf 末尾添加
vim /etc/rsyslog.conf
local0.* /var/log/keepalived.log
重启日志记录服务 systemctl restart rsyslog 重启 keepalived systemctl restart keepalived
此时,可以从 /var/log/keepalived.log 查看日志了。
参考资料 https://juejin.im/post/6844904071183220749 RabbitMQ 官方文档 —— 集群指南:www.rabbitmq.com/clustering.… RabbitMQ 官方文档 —— 高可用镜像队列:www.rabbitmq.com/ha.html HAProxy 官方配置手册:cbonte.github.io/haproxy-dco… KeepAlived 官方配置手册:www.keepalived.org/manpage.htm…