 mysql
mysql
# mysql基础知识
NoSQL体系 1.键值存储数据库 典型产品 Memcached、Redis、MemcacheDB、BerkeleyDB
2.列存储数据库 月薪1万5不要玩他 Cassandra,HBase
3.面向文档数据库 mongodb、CouchDB
mysql数据库主要应用范围:互联网,大中小型网站,游戏公司,电商平台。 mariadb 暂时不用
非关系型数据库
Memcached 纯内存缓存软件 Memcachedb
redis 数据都是缓存在内存中。区别是redis会周期性的把更新的数据写入磁盘
数据库方向 传统的关系型数据库:MySQL,Oracle 互联网最火MySQL,mariadb 什么是关系型数据库。 1、二维表格 2、MySQL和Oracle数据库,互联网运维最常用的是MySQL 3、通过SQL结构化查询语句存取数据 4、保持数据一致性方面很强。ACID理论 特点:读写更多的是和磁盘打交道,数据一致性,安全 缺点:速度慢
非关系型数据库: nosql 以高效,高性能为目的,凡是和效率性能无关的因素都尽可能 抛弃 作为关系型数据库的一个重要补充 memcached 纯内存缓存的软件 redis内存加持久化软件 数据类型更多 key-->value 键值对形式 stu001--->
# 1. mysql安装
# 1.1 编译安装5.7
https://sourceforge.net/projects/boost/files/boost/1.59.0/boost_1_59_0.tar.gz/download
yum install libgcrypt perl make cmake bison bison-devel zlib-devel libcurl-devel libarchivedevel boost-devel gcc gcc-c++ cmake ncurses ncurses-devel gnutls-devel libxml2-devel openssl-devel libevent-devel libaio-devel
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/usr/local/mysql/data -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DMYSQL_TCP_PORT=3306 -DMYSQL_USER=mysql -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_ARCHIVE_STORAGE_ENGINE=1 -DWITH_BLACKHOLE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DENABLE_DOWNLOADS=1 -DDOWNLOAD_BOOST=1 -DWITH_BOOST=/usr/local/boost
[root@mdw mysql]# echo "export PATH=$PATH:/home/mysql/bin">>/etc/profile
[root@mdw mysql]# source /etc/profile
mysqld --defaults-file=/etc/my.cnf --initialize --user='mysql' --log_error_verbosity --explicit_defaults_for_timestamp
shell> groupadd mysql
shell> useradd -r -g mysql mysql
shell> cd /usr/local
shell> tar zxvf /path/to/mysql-VERSION-OS.tar.gz
shell> ln -s full-path-to-mysql-VERSION-OS mysql
shell> cd mysql
shell> chown -R mysql .
shell> chgrp -R mysql .
shell> scripts/mysql_install_db --user=mysql
shell> chown -R root .
shell> chown -R mysql data
shell> bin/mysqld_safe --user=mysql &
\# Next command is optional
shell> cp support-files/mysql.server /etc/init.d/mysql.server
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
初始化数据库
./scripts/mysql_install_db --user=mysql --basedir=/opt/mysql --datadir=/opt/mysql/data
5.7以上改了,如果还是使用上面那个就会提示让你用--initialize命令
./bin/mysqld --initialize --user=mysql --basedir=/home/mysql --datadir=/home/mysql/data
./bin/mysqld --initialize --user=mysql --basedir=/home/mysql --datadir=/home/mysql/data
cp support-files/my-default.cnf /etc/my.cnf
2
3
4
5
修改mysql.server文件里面程序路径
复制mysql.server到/etc/rc.d/init.d/mysqld
# 1.2 yum安装
https://dev.mysql.com/downloads/repo/yum/
在线安装
wget http://repo.mysql.com/mysql-community-release-el6-5.noarch.rpm
rpm -ivh mysql-community-release-el6-5.noarch.rpm
yum install mysql-community-server
2
3
4
5
自Mysql5.7初始密码不再默认为空!!!
grep 'temporary password' /var/log/mysqld.log
配置环境变量
echo "export PATH=$PATH:/home/mysql/bin">>/etc/profile
source /etc/profile
sed -i 's#/usr/local/mysql#/application/mysql#g' /application/mysql/bin/mysqld_safe &
# 2. 基本命令
# 2.1 启动停止
#查看mysql服务是否正常,如果正常提示mysqld is alive
mysqladmin -uroot -pcentos ping
#关闭mysql服务,但mysqladmin命令无法开启
mysqladmin –uroot –pcentos shutdown
/etc/init.d/mysqld stop
kill -USR2 cat path/pid
推荐前两个方法
#关闭数据库
mysqladmin -uroot -p shutdown
# 2.2 创建和删除数据库
#创建数据库testdb
mysqladmin -uroot –pcentos create testdb
#删除数据库testdb
mysqladmin -uroot -pcentos drop testdb
# 2.3 初始化数据库
生成随机密码
mysqld --initialize --user=mysql --datadir=/data/mysql/3306
生成空密码
mysqld --defaults-file=/data/mysql/3306/my.cnf --datadir=/data/mysql/3306/data --initialize-insecure --user=mysql
# 2.4 其他命令
#日志滚动,生成新文件/var/lib/mysql/mariadb-bin.00000N
mysqladmin -uroot -pcentos flush-logs 切割binlog日志
show databases; 查看数据库
drop database test; 删除test数据库
删除特殊符号数据库
drop database db.name;
show tables; 查表
select user,host from mysql.user; 查看用户
select database(); 查看当前表
select user(); 查看当前用户
create database wordpress;
show character set; 查询支持字符集
show variables like 'character%';
create database test;
alter database test character set utf8;
SHOW VARIABLES LIKE 'auto_inc%';
# 2.5 创建表和数据
use test
create table t1(id int unsigned auto_increment primary key) auto_increment = 4294967294;
insert into t1 values(null);
select * from t1;
insert into t1 values(null);
select * from t1;
# 2.5.1 创建表
CREATE TABLE student (
id int UNSIGNED AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
age tinyint UNSIGNED,
gender ENUM('M','F') default 'M'
)ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
# 2.5.2 查询现存表创建新表
create table user select user,host from mysql.user;
通过复制现存的表的表结构创建,但不复制数据
desc student;
create table teacher like student;
desc teacher;
# 2.5.3 查看表的状态
show table status like 'student'\G
查看表
show table status \G
# 2.5.4 修改表
ALTER TABLE students RENAME s1;
ALTER TABLE s1 ADD phone varchar(11) AFTER name;
ALTER TABLE s1 MODIFY phone int;
ALTER TABLE s1 CHANGE COLUMN phone mobile char(11);
ALTER TABLE s1 DROP COLUMN mobile;
ALTER TABLE s1 character set utf8;
ALTER TABLE s1 change name name varchar(20) character set utf8;
ALTER TABLE students ADD gender ENUM('m','f');
ALETR TABLE students CHANGE id sid int UNSIGNED NOT NULL PRIMARY KEY;
ALTER TABLE students DROP age;
DESC students;
# 2.5.5 添加普通索引
alter table student index index_age(age);
通过N个字符建立索引
create index index_age on stuent(age(8));
根据多个列创建联合索引
create index ind_name_age on student(name,age);
#新建表无主键,添加和删除主键
alter table 表名 drop primary key; 【如果这个主键是自增的,先取消自增长.】
具体方法如下:
alter table articles modify id int ; 【重新定义列类型】
alter table articles drop primary key;
CREATE TABLE t1 SELECT * FROM students;
ALTER TABLE t1 add primary key (stuid);
ALTER TABLE t1 drop primary key ;
SELECT s.aage,s.ClassID FROM (SELECT avg(Age) AS aage,ClassID FROM
students WHERE ClassID IS NOT NULL GROUP BY ClassID) AS s WHERE
s.aage>30;
select stuid,name,age from students where age > (select avg(age)
from students);
DDL 数据定义语言(CREATE,ALTER,DROP) 运维
DML 数据控制语言 (SELECT,INSERT,DELETE,UPDATE) 开发
DCL 数据控制语言 (GRANT,REVOKE,COMMIT,ROLIBACK) 运维
字符类型
INT [(M)] 正常大小整数类型
CHAR(M)定长字符串类型,当存储时,总是用空格填满右边到指定的长度。
VARCHAR 变长字符串类型
# 2.5.6 查看表的结构
desc student;
show columns from student;
更新频繁,读取比较少的表要少建立索引
尽量选择在唯一值多的大表上建立索引
要在表的列上创建索引
索引会加快查询速度,但是会影响更新的速度
索引不是越多越好,要在频繁查询的where后的条件列上创建索引
小表或唯一值极少的列上不建索引,要在大表以及不同内容多的列上创建索引。
# 2.5.7 插入数据 insert
insert into 表名 字段名1 字段名n values 值1 值n
CREATE TABLE test (
id int(4) NOT NULL AUTO_INCREMENT,
name char(20) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1;
insert into test(id,name) values(1,'oldboy');
按顺序插入
insert into test values(3,'inca');
insert into student values(3,'老男孩');
批量插入
insert into test values(4,'zuma'),(5,'kaka');
insert into test values(1,'oldboy'),(2,'dd'),(3,'inca'),(4,'zuma'),(5,'kaka');
删除表数据
delete from test;
# 2.6 查询数据
select 字段1,字段2 from 表名 where 表达式
select * from test;
select user,host from mysql.user;
select user,host from mysql.user where user='root';
select user,host from mysql.user where user='root' and host='zabbix';
select user,host from mysql.user where user='root' or host='zabbix';
select id,name from test where id>2 and id<4;
select id,name from test order by id desc;
# 2.6.1 多表查询
select student.Sno,student.Sname,course.Cname,SC.Grade from student,SC,course where student.Sno=SC.Sno and course.Cno=SC.Cno order by Sno;
字符类型查询要带引号
explain select * from test where name='oldboy'\GRANT
# 2.6.2 修改表中数据 update
修改表中指定条件固定列的数据
update 表名 set 字段=新值,--- where 条件
update test set name='gongli' where id=3;
# 2.6.3 删除表中的数据 delete
delete from test where id=1;
delete from test where id>1;
清空表 truncate table test;
truncate删除更快,清空物理文件,delete是按逻辑清除,按行删。
# 2.6.4 更改表名
rename table test to test1;
alter table test1 rename to test;
mysql -uroot -p --default-character-set=latin1 </backup/all.sql
set names utf8;
统一字符集保证不乱码
# 2.6.5 测试数据
create table class(
cid int(10),
cdesc varchar(20)
);
create table student(
sid int(10),
name varchar(20),
age int(3),
cid int(10)
);
create table teacher(
tid int(10),
name varchar(20),
cid int(10)
);
insert into class values(1, "PHP"),(2, "Java"),(3, "C++"),(4,"SQL");
insert into student values(1, "s1",16,1),(2, "s2",17,2),(3, "s3",18,3),(4,"s4",19,4),(5, "s5",18,3),(6,"s6",19,4);
insert into teacher values(1, "t1",1),(2, "t2",2),(3, "t3",3),(4,"t4",4);
alter table student add constraint sid_pk primary key(sid);
# 2.6.6 连接查询 join
连接查询方式有:内连接、外连接(常用,分为左连接和右连接)、自然连接、交叉连接。借助连接查询,可以同时查看多张表中的数据。
内连接:有条件连接,用 on 在多个表之间指定条件连接。如果两个表的任一个匹配不到数据,则返回空
外连接:有条件连接,用 on 在多个表之间指定条件连接。只要主表(左连接的左表,右连接的右表)匹配到数据,就不会返回空,未匹配到数据的字段填充 NULL
mysql> select * from class join student on student.cid = class.cid where class.cid = 1;
Empty set (0.00 sec)
mysql> select * from class left join student on student.cid = class.cid where class.cid = 1;
+-----+-------+------+------+------+------+
| cid | cdesc | sid | name | age | cid |
+-----+-------+------+------+------+------+
| 1 | PHP | NULL | NULL | NULL | NULL |
+-----+-------+------+------+------+------+
1 row in set (0.00 sec)
mysql> select * from student left join class on student.cid = class.cid where class.cid = 1;
Empty set (0.00 sec)
语法
内连接:select 字段列表 from 左表 [inner] join 右表 on 左表.字段 = 右表.字段;
外连接(重要):
左外连接:select 字段列表 from 左表 left join 右表 on 左表.字段 = 右表.字段;
右外连接:select 字段列表 from 左表 right join 右表 on 左表.字段 = 右表.字段;
自然连接:有条件连接,但是不需要指定,MySQL 自动依据“同名字段”连接(多个同名字段就都作为条件)。
交叉连接 cross join:无条件连接,取笛卡尔积,返回的记录数等于各表记录数的乘积。
# 2.6.7 联合查询 union
将多个查询结果进行拼接,多个查询结果的字段数必须相同,类型可以不同。支持两个选项:
all:不对相同结果去重,默认选项
distinct:去重
mysql> select age from student union distinct select cdesc from class;
+------+
| age |
+------+
| 17 |
| 18 |
| 19 |
| C++ |
| Java |
| PHP |
| SQL |
+------+
7 rows in set (0.00 sec)
# 2.6.8 子查询
from 子查询:from 后面是子查询。注意这个子查询会创建临时表,需要为其起个别名:
mysql> select sid from (select * from student where sid > 2);
ERROR 1248 (42000): Every derived table must have its own alias
mysql> select sid from (select * from student where sid > 2) as s;
+-----+
| sid |
+-----+
| 3 |
| 4 |
| 5 |
| 6 |
+-----+
4 rows in set (0.00 sec)
where 子查询:where 后面是子查询。
mysql> select * from student where age > (select age from student where sid = 3);
+-----+------+------+------+
| sid | name | age | cid |
+-----+------+------+------+
| 4 | s4 | 19 | 4 |
| 6 | s6 | 19 | 4 |
+-----+------+------+------+
2 rows in set (0.00 sec)
where exists 子查询:where exists 后面是子查询。
mysql> select * from class where exists(select * from student where cid=1);
Empty set (0.00 sec)
mysql> select * from class where exists(select * from student where cid=2);
+-----+-------+
| cid | cdesc |
+-----+-------+
| 1 | PHP |
| 2 | Java |
| 3 | C++ |
| 4 | SQL |
+-----+-------+
4 rows in set (0.00 sec)
# 3. mysql用户管理
# 3.1 权限表
# 3.1.1 user表
1、用户列 2、权限列 3、安全列 4、资源控制列
# 3.1.2 db表和host表
db表中存储了用户对某个数据库的操作权限
# 3.1.3 tables_priv表和columns_priv表
# 3.1.4 procs_priv表
# 3.2 账户管理
# 3.2.1 登录和退出
mysql -h localhost -u root -p test
-h 主机名
-u 用户名 -p 密码
-P 端口号
-e 执行SQL语句
# 3.2.2 新建普通用户
# 1、使用create 创建用户
create user 用户名@授权地址 identified by '密码'
create user 'root'@'%' identified by 'mypass'; create user 'root'@'localhost';
# 2、使用grant语句新建用户
grant privileges on db.table to user@host identified by 'password'; grant select,update on . to 'test'@'localhost' identified by 'test'; select host,user,select_priv,update_priv from mysql.user where user='test';
# 3、直接操作mysql用户表
insert into mysql.user(host,user,password,privilegelist) values ('host','username',password('password'),privilegevaluelist);
insert into user (host,user,password) values('localhost','customer1',password('custoer1'));
# 3.2.3 删除普通用户
# 1、使用drop user语句删除用户
drop user 'test'@'localhost';
# 2、使用delete语句删除用户
delete from mysql.user where user="root" annd host= "A"; 相当于 drop user 'root'@'A';
# 3.2.4 root用户修改自己的密码
# 1、使用mysqladmin修改密码
mysqladmin -uroot password "123456"
mysqladmin -uroot -p123456 password "oldboy"
# 2、修改mysql数据库的user表
update mysql.user set password=password("rootpwd") where user="root" and host="localhost";
# 3、使用set语句修改root用户的密码
set password=password("rootpwd");
# 3.2.5 root用户修改普通用户的密码
# 1、使用SET语句修改普通用户密码
set password for 'user'@'host'=password('somepassword'); 普通用户可省略for子句 set password=password('somepassword');
set password for 'test'@'localhost'=password("newpwd"):
# 2、使用update语句修改普通用户的密码
update mysql.user set password=password("pwd") where user="username" and host="hostname";
3、使用grant语句修改普通用户密码
grant usage on . to 'someuser'@'%' identified by 'somepassword';
# 3.2.6 alter更改用户名密码,官方推荐使用alter
ALTER USER test@'%' IDENTIFIED BY '123456';
#mariadb 10.3
update mysql.user set authentication_string=password('123456') where
user='root';
#此方法需要执行下面指令才能生效:
FLUSH PRIVILEGES;
重命名用户
RENAME USER old_user_name TO new_user_name;
# 3.2.7 忘记管理员密码的解决办法:
启动mysqld进程时,为其使用如下选项: --skip-grant-tables --skip-networking
1、mysqld_safe --skip-grant-tables --user=mysql 2、mysql -u root
update mysql.user set password=password('newpwd') where user='root' and host='localhost';
flush privileges;
# 3.3 权限管理
# 3.3.1 mysql权限表
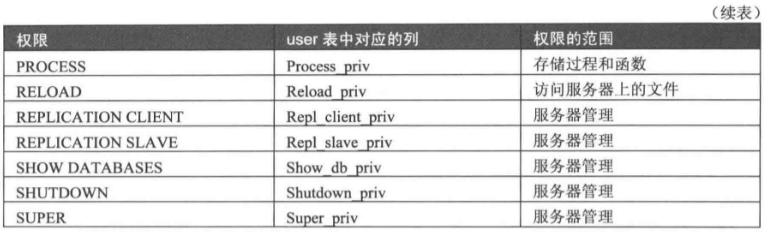
# 3.3.2 授权
# 1、全局层级
grant all on *.* 和 revoke all on *.* 只授予和撤销全局权限
# 2、数据库层级
存储在mysql.db和mysql.host表中,grant all on db_name. 和REVOKE ALL ON db_name.*只授予和撤销数据库权限
# 3、表层级
存储在mysql.tables_priv表中。grant all on db_name.tbl_name和revoke all on db_name.tbl_name只授予和撤销表权限
# 4、列层级
存储在Mysql.columns_priv表中。当使用REVOKE时,必须指定与被授权列相同的列
# 5、子程序层级
create routing 、alter routing、execute和grant权限适用于已存储的子程序。这些权限可以被授予为全局层级和数据库层级。而且,除了create routing外,这些权限可以被授予子程序层级,并存储在mysql.procs_priv表中
grant select,insert on . to 'grantuser'@'localhost' identified by 'grantpwd' with grant option;
# 3.3.3 取消授权
取消授权:REVOKE
REVOKE DELETE ON testdb.* FROM 'testuser'@‘172.16.0.%’;
查询授权
SHOW GRANTS FOR 'user'@'host';
SHOW GRANTS FOR CURRENT_USER[()];
# 4. 多实例创建
mysqld --defaults-file=/data/mysql/3307/my.cnf --datadir=/data/mysql/3307/data --initialize-insecure --user=mysql
准备程序文件
准备环境变量
准备cnf配置文件
cnf配置文件格式
[mysqld] [mysqld_safe] [mysqld_multi] [mysql] [mysqldump] [server] [client] 格式:parameter = value
说明:_和- 相同 1,ON,TRUE意义相同, 0,OFF,FALSE意义相同
mysqld --initialize --user=mysql --datadir=/data/mysql
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chkconfig --add mysqld
service mysqld start
#修改root密码
mysqladmin –uroot –pcentos password ‘magedu’
# 4.1 传统多实例创建
mkdir -pv /mysql/{3306,3307,3308}/data
chown -R mysql.mysql /mysql
5.6
mysql_install_db --basedir=/application/mysql --defaults-file=/data/3306/my.cnf --datadir=/data/3306/data
5.7
mysqld --initialize --user=mysql --datadir=/data/mysql
# 4.2 配置开机自启动脚本&启动多实例
cd /home/coco/tools/mysql-5.5.32
/bin/cp support-files/mysql.server /data/3306/mysql
# 4.3 多实例启动文件的停止mysql服务:
mysqladmin -u root -poldboy123 -S /data/3306/mysql.sock shutdown
mysqladmin -u root -poldboy123 -S /data/3307/mysql.sock shutdown
# 4.4 mysqld_safe启动多实例
mysqld_safe --defaults-file=/data/3306/my.cnf 2>&1 > /dev/null &
mysqld_safe --defaults-file=/data/3307/my.cnf 2>&1 > /dev/null &
# 4.5 5.7官方多实例创建
mkdir -pv /mysql/{3306,3307,3308}/data
chown -R mysql.mysql /mysql
cp /usr/local/mysql/support-files/mysqld_multi.server /etc/rc.d/init.d/mysqld_multi
创建和修改my.cnf
/etc/rc.d/init.d/mysqld_multi start 1-3
登录 mysql -uroot -p -S /data/mysql/3306/mysql.sock
# 5. 主从复制
master.info:用于保存slave连接至master时的相关信息,例如账号、密码、服务器地址等
relay-log.info:保存在当前slave节点上已经复制的当前二进制日志和本地relay log日志的对应关系
主节点配置: (1) 启用二进制日志
为当前节点设置一个全局惟一的ID号
遇到问题解决流程
1、遇到的问题把报错和日志记录下
2、尝试解决的方案记录
3、解决以后总结成文档保存
4、少截图,多发文本内容
# 5.1 主从同步配置步骤
1、准备两台数据库环境,或者单台多实例环境,正常启动和登录。
2、配置my.cnf文件,主库配置log-bin和server-id参数,从库配置server-id,不能和主库及其他库一样,一般不开启库log-bin功能。
3、登录主库增加用于从库连接主库同步的账户例如;rep,并授权replication slave同步的权限
4、登录主库,整库锁表flush tables with read lock 然后show master status 查看binlog的位置状态
5、新开窗口,linux命令行备份或导出原有的数据库数据,并拷贝到从库所在的服务器目录。
如果数据库量很大,并且允许停机,可以停机打包,而不用mysqldump.
6、解锁主库,unlock tables;
7、把主库导出的原有数据恢复到从库
8、根据主库的show master status查看binlog的位置状态
9、从库开启同步开关,start slave
10、show slave status 检查同步状态
1.4 全局锁两种方法
# 5.2 自动解锁参数
interactive_timeout = 60
wait_timeout =60
默认情况时长
show variables like '%timeout%';
调整参数
set global interactive_timeout = 60;
set global wait_timeout =60;
show master status;
# 5.3 从库
relay-log=relay-log-bin#日志文件
relay-log-index=slave-relay-bin.index
# 5.4 授权用户 有同步权限
grant replication slave on . to 'rep'@'192.168.200.237' identified by '123456';
锁表
flush tables with read lock;
备份
mysqldump -uroot -p -A -B --events --master-data=1|gzip >/tmp/rep.sql.gz
解锁
unlock tables;
导入到从库
mysql -uroot -p <rep.sql
从库开启同步参数
change master to
master_host='mysql.ops.com',master_user='rep',master_password='123456',master_log_file='mysql-bin.000048',master_log_pos= 14504956;
start slave;
CHANGE MASTER TO MASTER_HOST='masterhost',
MASTER_USER='repluser',
MASTER_PASSWORD='replpass',
MASTER_LOG_FILE='mariadb-bin.xxxxxx',
MASTER_LOG_POS=#;
START SLAVE [IO_THREAD|SQL_THREAD];
SHOW SLAVE STATUS;
# 5.5 主服务器运行一段时间后,新增从节点服务器
mysqldump -uadmin -p -A -F --single-transaction --master-data=1 >/data/mysqlbak/fullbackup_$(date +%F_%T).sql
grep '^CHANGE MASTER' /data/fullbackup_2019-11-27_17:41:17.sql
CHANGE MASTER TO
MASTER_HOST='192.168.200.235',
MASTER_USER='rep',
MASTER_PASSWORD='123456',
MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000004',
MASTER_LOG_POS=154;
start slave;
# 5.6 1236数据不同步错误解决
在主库 flush logs;
show master status; 记录binlog文件和POS号
从库停止slave,重新change master to
mysql >CHANGE MASTER TO MASTER_LOG_FILE='log-bin.000005',MASTER_LOG_POS=107;
开启从库同步
# 5.7 复制冲突
#方法1
MariaDB [(none)]> stop slave;
MariaDB [(none)]> set global sql_slave_skip_counter=1;
MariaDB [(none)]> start slave;
#方法2
[root@slave1 ~]#vim /etc/my.cnf.d/mariadb-server.cnf
[mysqld]
slave_skip_errors=1007|ALL
[root@slave1 ~]#systemctl restart mariadb
当master服务器宕机,提升一个slave成为新的master
#找到哪个从节点的数据库是最新,让它成为新master
[root@centos8 ~]#cat /var/lib/mysql/relay-log.info
#新master修改配置文件,关闭read-only配置
[root@slave1 ~]#vim /etc/my.cnf.d/mariadb-server.cnf
#清除旧的master复制信息
MariaDB [hellodb]>set global read_only=off;
MariaDB [hellodb]>stop slave;
MariaDB [hellodb]>reset slave all;
#在新master上完全备份
#其它所有 slave 重新还原数据库,指向新的master
#在中间级联slave实现
[root@centos8 ~]#vim /etc/my.cnf.d/mariadb-server.cnf
[mysqld]
server-id=18
log-bin
read-only
log_slave_updates #级联复制中间节点的必选项
# 5.8 造成主从不一致的原因
主库binlog格式为Statement,同步到从库执行后可能造成主从不一致。
主库执行更改前有执行set sql_log_bin=0,会使主库不记录binlog,从库也无法变更这部分数据。
从节点未设置只读,误操作写入数据
主库或从库意外宕机,宕机可能会造成binlog或者relaylog文件出现损坏,导致主从不一致
主从实例版本不一致,特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面可能不支持该功能
MySQL自身bug导致
# 5.9 手动重建不一致的表
\1. 如何避免主从不一致
主库binlog采用ROW格式
主从实例数据库版本保持一致
主库做好账号权限把控,不可以执行set sql_log_bin=0
从库开启只读,不允许人为写入
定期进行主从一致性检验
忽略授权表同步 修改my.cnf
binlog-ignore-db = mysql
binlog-ignore-db = performance_schema
binlog-ignore-db = information_schema
忽略某些错误
slave_skip-errors=1032,1062,1007
需要从库开户binlog的情况
1.当前从库还要作为其他从库的主库
2.把从库作为备份服务器是需要开启binlog
vim /etc/my.cnf
log-bin = mysql-bin
log-slave-updates
expire_logs_days = 7
把从库提升为主库
确保所有relay log全部更新完毕 stop slave; show processlist;
stop slave;
进到数据库目录,删除master.info relay-log.info
检查授权表,read-only等参数
开启log-bin
删除 log-slave0updates
重启从库
其他从库操作
stop slave;
change master to master_host ='192.168.200.237'; //如果不同步 ,就指定位置点
start slave;
show slave status\G
双主及多主同步
master1:
auto_increment_increment =2 #自增ID的间隔 如1 3 5 间隔为2
auto_increment_offset = 1 # ID的初始位置
master2:
auto_increment_increment =2 #自增ID的间隔 如2 4 6 间隔为2
auto_increment_offset = 2 # ID的初始位置
mysqldump -uroot -p -A -B --master-data=1 -x --events >/tmp/rep.sql
# 6. 备份工具
cp, tar等复制归档工具:物理备份工具,适用所有存储引擎;只支持冷备;完全和部分备份
LVM的快照:先加读锁,做快照后解锁,几乎热备;借助文件系统工具进行备份
mysqldump:逻辑备份工具,适用所有存储引擎,对MyISAM存储引擎进行温备;支持完全或部分备份;对InnoDB存储引擎支持热备,结合binlog的增量备份
xtrabackup:由Percona提供支持对InnoDB做热备(物理备份)的工具,支持完全备份、增量备份
MariaDB Backup: 从MariaDB 10.1.26开始集成,基于Percona XtraBackup 2.3.8实现
mysqlbackup:热备份, MySQL Enterprise Edition组件
mysqlhotcopy:PERL 语言实现,几乎冷备,仅适用于MyISAM存储引擎,使用LOCK TABLES、FLUSH TABLES和cp或scp来快速备份数据库
# 6.1 基于LVM的快照备份
(1) 请求锁定所有表 mysql> FLUSH TABLES WITH READ LOCK;
(2) 记录二进制日志文件及事件位置
mysql> FLUSH LOGS;
mysql> SHOW MASTER STATUS;
mysql -e 'SHOW MASTER STATUS' > /PATH/TO/SOMEFILE
(3) 创建快照 lvcreate -L # -s -p r -n NAME /DEV/VG_NAME/LV_NAME
(4)释放锁 mysql> UNLOCK TABLES;
(5) 挂载快照卷,执行数据备份
(6) 备份完成后,删除快照卷
(7) 制定好策略,通过原卷备份二进制日志
# 6.2 mysqldump备份工具
mysqldump [OPTIONS] database [tables] #支持指定数据库和指定多表的备份,但数据库
本身定义不备份
mysqldump [OPTIONS] –B DB1 [DB2 DB3...] #支持指定数据库备份,包含数据库本身定义也
会备份
mysqldump [OPTIONS] –A [OPTIONS] #备份所有数据库,包含数据库本身定义也会备
份
-A, --all-databases #备份所有数据库,含create database
-B, --databases db_name… #指定备份的数据库,包括create database语句
-E, --events:#备份相关的所有event scheduler
-R, --routines:#备份所有存储过程和自定义函数
--triggers:#备份表相关触发器,默认启用,用--skip-triggers,不备份触发器
--default-character-set=utf8 #指定字符集
--master-data[=#]: #此选项须启用二进制日志
#1:所备份的数据之前加一条记录为CHANGE MASTER TO语句,非注释,不指定#,
默认为1,适合于主从复制多机使用
#2:记录为被注释的#CHANGE MASTER TO语句,适合于单机使用
#此选项会自动关闭--lock-tables功能,自动打开-x | --lock-all-tables功能(除非开
启--single-transaction)
-F, --flush-logs #备份前滚动日志,锁定表完成后,执行flush logs命令,生成新的二进
制日志文件,配合-A 或 -B 选项时,会导致刷新多次数据库。建议在同一时刻执行转储
和日志刷新,可通过和--single-transaction或-x,--master-data 一起使用实现,此时
只刷新一次二进制日志
--compact #去掉注释,适合调试,生产不使用
-d, --no-data #只备份表结构
-t, --no-create-info #只备份数据,不备份create table
-n,--no-create-db #不备份create database,可被-A或-B覆盖
--flush-privileges #备份mysql或相关时需要使用
-f, --force #忽略SQL错误,继续执行
--hex-blob #使用十六进制符号转储二进制列,当有包括BINARY, VARBINARY,
BLOB,BIT的数据类型的列时使用,避免乱码
-q, --quick #不缓存查询,直接输出,加快备份速度
mysqldump 最常用的备份工具
逻辑备份:小于50G的数据量
mysqldump -uroot -p -B -A -x >/tmp/backup.sql
-A 备份所有库
-B 备份多个库,并添加use 库名:create database库等的功能
-x 锁表,会影响读写,尽量晚上执行
锁表备份多个库
mysqldump -uroot -p -B -x mysql >/tmp/backup.sql
mysqldump --socket=/var/lib/mysql/mysql.sock -uroot -p -B -x mysql >/tmp/backup.sql
mysqldump -uroot -p123456 -B -x wordpress|gzip >/backup/wordpress_"$(date +%F)".sql.gz &&
2
3
4
5
备份表
mysqldump -uroot -p books test >/tmp/test.sql
物理备份
scp
# 备份策略
InnoDB建议备份策略 mysqldump –uroot -p –A –F –E –R --single-transaction --master-data=1 --flushprivileges --triggers --default-character-set=utf8 --hex-blob >${BACKUP}/fullbak_${BACKUP_TIME}.sql
MyISAM建议备份策略 mysqldump –uroot -p –A –F –E –R –x --master-data=1 --flush-privileges --triggers -- default-character-set=utf8 --hex-blob >${BACKUP}/fullbak_${BACKUP_TIME}.sql
实战案例:分库备份并压缩
mysql -uroot -e 'show databases'|sed -rn '/^(Database|information_schema|performance_schema)$/!s#(.*)#mysqldump -B \1 | gzip > /data/\1.sql.gz#p' |bash
完全备份和还原
mysqldump -uroot -pmagedu -A -F --single-transaction --master-data=2 |gzip > /backup/all-date +%F.sql.gz
备份单个表 mysqldump -uroot -p oldboy student
备份数据库表结构 mysqldump -uroot -p -d oldboy
如果希望只导出数据 -t
利用二进制日志,还原数据库最新状态
mysqldump -uroot -pmagedu -A -F --default-character-set=utf8 --single-transaction --master-data=2 | gzip > /backup/all_date +%F.sql.gz
show master logs;
mysqlbinlog mysql-bin.000001 --start-position=328 >/backup/inc.sql mysqlbinlog mysql-bin.000002 >> /backup/inc.sql
恢复误删除的表
#完全备份
[root@centos8 ~]#mysqldump -uroot -p -A -F --single-transaction --master-data=2 > /backup/allbackup_date +%F_%T.sql
#10:00误删除了一个重要的表 MariaDB [testdb]> drop table students; Query OK, 0 rows affected (0.021 sec)
#从完全备份中,找到二进制位置 [root@centos8 ~]#grep '-- CHANGE MASTER TO' /backup/allbackup_2019-11- 27_10:20:08.sql -- CHANGE MASTER TO MASTER_LOG_FILE='mariadb-bin.000003', MASTER_LOG_POS=389;
#备份从完全备份后的二进制日志 [root@centos8 ~]#mysqlbinlog --start-position=389 /var/lib/mysql/mariadbbin. 000003 > /backup/inc.sql
#找到误删除的语句,从备份中删除此语句,如果文件过大,可以使用sed实现
[root@centos8 ~]#vim /data/inc.sql
#DROP TABLE student_info /* generated by server */
#利用完全备份和修改过的二进制日志进行还原 [root@centos8 ~]#mysql -uroot -p MariaDB [hellodb]> set sql_log_bin=0; MariaDB [hellodb]> source /backup/allbackup_2019-11-27_10:20:08.sql;
MariaDB [hellodb]> source /backup/inc.sql MariaDB [hellodb]> set sql_log_bin=1;
show full processlist; dhow global status; 很重要,分析并做好监控 mysql -uroot -p123456 -S /data/mysql/3306/mysql.sock -e 'show global status\G' show variables;
在线修改参数 先在mysql里面改,然后再在my.cnf修改
按照位置截取 mysqlbinlog mysqlbin.000002 --start-position=365 --stop-position=456 -r pos.sql
# 6.3 xtrabackup 开源的物理备份工具
https://www.percona.com/doc/percona-xtrabackup/2.4/backup_scenarios/full_backup.html
工作原理
https://www.percona.com/doc/percona-xtrabackup/2.4/how_xtrabackup_works.html#how-xtrabackup-works
# 6.4 xtrabackup安装
2.4安装 yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL libev numactl wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm percona-release enable-only tools release yum install percona-xtrabackup-24 yum install percona-xtrabackup-80 yum localinstall percona-xtrabackup-80-8.0.4-1.el7.x86_64.rpm
innobackupex [option] BACKUP-ROOT-DIR
xtrabackup工具备份和还原,需要三步实现
- 备份:对数据库做完全或增量备份
- 预准备: 还原前,先对备份的数据,整理至一个临时目录,
- 还原:将整理好的数据,复制回数据库目录中 --user:#该选项表示备份账号 --password:#该选项表示备份的密码 --host:#该选项表示备份数据库的地址 --databases:#该选项接受的参数为数据库名,如果要指定多个数据库,彼此间需要以 空格隔开;如:"xtra_test dba_test",同时,在指定某数据库时,也可以只指定其中的 某张表。如:"mydatabase.mytable"。该选项对innodb引擎表无效,还是会备份所有 innodb表 --defaults-file:#该选项指定从哪个文件读取MySQL配置,必须放在命令行第一个选项 位置 --incremental:#该选项表示创建一个增量备份,需要指定--incremental-basedir --incremental-basedir:#该选项指定为前一次全备份或增量备份的目录,与-- incremental同时使用 --incremental-dir:#该选项表示还原时增量备份的目录 --include=name:#指定表名,格式:databasename.tablename
innobackupex --defaults-file=/data/mysql/3307/my.cnf --socket=/data/mysql/3307/mysql.sock --user=root --password=123456 /backup
Prepare预准备
innobackupex --apply-log [option] BACKUP-DIR
--apply-log:#一般情况下,在备份完成后,数据尚且不能用于恢复操作,因为备份的数 据中可能会包含尚未提交的事务或已经提交但尚未同步至数据文件中的事务。因此,此时 数据文件仍处理不一致状态。此选项作用是通过回滚未提交的事务及同步已经提交的事务 至数据文件使数据文件处于一致性状态 --use-memory:#和--apply-log选项一起使用,当prepare 备份时,做crash recovery 分配的内存大小,单位字节,也可1MB,1M,1G,1GB等,推荐1G --export:#表示开启可导出单独的表之后再导入其他Mysql中 --redo-only:#此选项在prepare base full backup,往其中合并增量备份时候使用, 但不包括对最后一个增量备份的合并
还原 innobackupex --copy-back [选项] BACKUP-DIR innobackupex --move-back [选项] [--defaults-group=GROUP-NAME] BACKUP-DIR
--copy-back:#做数据恢复时将备份数据文件拷贝到MySQL服务器的datadir --move-back:#这个选项与--copy-back相似,唯一的区别是它不拷贝文件,而是移 动文件到目的地。这个选项移除backup文件,用时候必须小心。使用场景:没有足够的 磁盘空间同事保留数据文件和Backup副本 --force-non-empty-directories #指定该参数时候,使得innobackupex --copy-back 或--move-back选项转移文件到非空目录,已存在的文件不会被覆盖。如果--copy-back和--move-back文件需要从备份目录拷贝一个在datadir已经存在的文件,会报错 失败
innobackupex --defaults-file=/etc/my.cnf --copy-back --rsync /backup/mysql/2014-04-07_23-05-04/
增量备份恢复
增量备份的恢复大体为3个步骤
*恢复完全备份
*恢复增量备份到完全备份(开始恢复的增量备份要添加--redo-only参数,到最后一次增量备份去掉--redo-only参数)
*对整体的完全备份进行恢复,回滚那些未提交的数据
恢复完全备份(注意这里一定要加--redo-only参数,该参数的意思是只应用xtrabackup日志中已提交的事务数据,不回滚还未提交的数据)
innobackupex --apply-log --redo-only /backup/mysql/full/2014-04-07_23-37-20/
恢复增量1 innobackupex --apply-log --redo-only /backup/mysql/full/2014-04-07_23-37-20/ --incremental-dir=/backup/mysql/incremental/2014-04-07_23-42-46/ 恢复增量2 innobackupex --apply-log /backup/mysql/full/2014-04-07_23-37-20/ --incremental-dir=/backup/mysql/incremental/2014-04-07_23-51-15/
把所有合在一起的完全备份整体进行一次apply操作,回滚未提交的数据: innobackupex --apply-log /data/backup/full/2014-04-07_23-37-20/ innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup/2018-07-30_11-04-55/
xtrabackup主从同步
https://www.cnblogs.com/pangguoping/p/5746087.html
1.主库机器上创建备份目录
# mkdir -p /backup/full_data
2.执行全库备份
2.1.备份
# innobackupex --defaults-file=/etc/my.cnf --user=root --password=123 --socket=/tmp/mysql.sock /data/backup/full_data
PS:备份完成后,会在/backup/full_data/目录下生成一个时间点的目录,这里是2016-07-14_05-19-52。你也可以加一个--no-timestamp参数不产生这个目录,直接备份到/backup/full_data/目录下
2
2.2.重放redo log
#下面preparing,undo撤销未提交的事务,重放redo log
# innobackupex --defaults-file=/etc/my.cnf --user=root --password=123 --apply-log --socket=/tmp/mysql.sock /data/backup/full_data/2016-07-14_05-19-52
2
# 6.5 全量及增量备份mysql
1.按天全备
周一00点全量备份 增量备份
周二00点全量备份 增量备份
优点:恢复时间短,维护成本低
缺点:占用空间多,占用资源多,经常锁表影响用户体验。
2.按周全备
周一到周日增量数据备份
周六00点全量备份
优点:占用空间小,占用系统资源少,无需锁表,用户体验好一些
缺点:维护成本高,恢复麻烦,时间长
全量和增量的频率
1、中小企业全量一般是一天一次,业务流量低谷执行全备,备份时会锁表
2、单台数据库,用RSYNC把所有binlog定时备份到远程服务器,尽量做主从复制
3、大公司周备,每周六00点古曲网全量,其他时间都是增量
优点:节省备份时间,减小备份压力。缺点:增量的binlog文件副本太多,还原会很麻烦
4、一主多从,会有一个从库做备份,延迟同步
mysqldump备份什么时候用
1、迁移或升级数据库
2、增加从库
3、主库或从库宕机,主从可以互相切换,无需备份。
4、人为的DDL,DML语句,主从库没办法了,所有库都会执行。此时需要备份。
5、跨机房灾备,需要备份到异地
增量恢复必备条件
开启bin-log
存在一份全备加上全备之后的时刻到出问题时刻的所有增量binlog文件备份
刷新binlog
mysqladmin -uroot -p -S /data/mysql/3308/mysql.sock flush-logs
停止一个从库,然后在主库刷新binlog,把mysqlbin导入到sql(去掉出错的语句)
把全备的备份和增量sql恢复到从从库
停止主库,快速把刷新binlog以后的数据解析为sql恢复到从库
切换从库为主库提供服务
增量恢复
人为SQL造成的误操作
全备和增量
恢复是建议对外停止更新
恢复全量,然后把增量日志中有问题的SQL语句删除,再导入增量
# 7. mysql 日志
错误日志 error log 普通查询日志 general query log 慢查询日志 slow query log 二进制日志 binary log
show variables like '%log%';
general_log general_log_file
slow_query_log long_query_time = 1 log-slow-queries = /data/slow.log log_queries_not_using_indexes
error_log
手动刷新binlog日志(每次重启mysql都会自动刷新) flush logs; 清空binlog日志 reset master
# 7.1 mysql中binlog_format的三种模式
mysql复制主要有三种方式:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
① STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)
② ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
③ MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
binlog_format = MIXED //binlog日志格式,mysql默认采用statement,建议使用mixed
log-bin = /data/mysql/mysql-bin.log //binlog日志文件
expire_logs_days = 7 //binlog过期清理时间
max_binlog_size = 100m //binlog每个日志文件大小
binlog_cache_size = 4m //binlog缓存大小
max_binlog_cache_size = 512m //最大binlog缓存大小
mysqladmin -uroot -p flush-logs
# 7.2 清理binlog日志
空间被binlog日志占满,导致MySQL数据库出错。
使用下面方法可以安全清理binlog日志
# 7.2.1 没有主从同步的情况下清理日志
mysql -uroot -p123456 -e 'PURGE MASTER LOGS BEFORE DATE_SUB( NOW( ),INTERVAL 5 DAY)';
#mysql 定时清理5天前的binlog
mysql -u root -p #进入mysql 控制台
reset master; #重置binlog
# 7.2.2 MySQL主从同步下安全清理binlog日志
1、mysql -u root -p #进入从服务器mysql控制台
show slave status\G; #检查从服务器正在读取哪个日志,有多个从服务器,选择时间最早的一个做为目标日志。
2、进入主服务器mysql控制台
show master log; #获得主服务器上的一系列日志
PURGE MASTER LOGS TO 'binlog.000058'; #删除binlog.000005之前的,不包括binlog.000058
PURGE MASTER LOGS BEFORE '2016-06-22 13:00:00'; #清除2016-06-22 13:00:00前binlog日志
PURGE MASTER LOGS BEFORE DATE_SUB( NOW( ), INTERVAL 3 DAY); #清除3天前binlog日志
# 7.2.3 设置自动清理MySQL binlog日志
vi /etc/my.cnf #编辑配置
expire_logs_days = 15 #自动删除15天前的日志。默认值为0,表示从不删除。
log-bin=mysql-bin #注释掉之后,会关闭binlog日志
binlog_format=mixed #注释掉之后,会关闭binlog日志
:wq! #保存退出
# 7.3 mysqlbinlog 恢复数据
确认已经开启binlog日志
恢复前备份数据,刷新binlog文件
可以在数据备份之前或者之后执行flush logs重新生成一个binlog日志用来记录备份之后的所有增删改操作(重新生成日志更好找pos点)
flush logs
恢复的数据只是截止到备份时间的数据,剩下缺少的数据可以通过binlog日志来恢复,由于我们备份数据库之前重新刷新了日志6,所以备份后的所有操作都保存在这个新日志中,可以先备份下这个日志文件,再创建一个新日志7
重新创建一个日志7的目的:接下来所有操作的数据都会写入到日志7中,日志6中不会在写入任何数据(方便根据日志6的内容恢复数据,因为日志6的数据就是备份之后到删库之前的所有操作日志,重建日志7不会有过多的数据影响恢复)
mysqlbinlog --no-defaults --base64-output=decode-rows -v -v /var/mysql/data/mysql81-bin.000113 | grep -B 15 -A 15 'DELETE FROM'
拷贝mysql81-bin.000113文件中的删除记录到指定文件中/var/mysql/data/delete.txt:
:/usr/local/mysql/bin>$./mysqlbinlog --no-defaults --base64-output=decode-rows -v -v /var/mysql/data/mysql81-bin.000113| sed -n '/### DELETE FROM '`pluto_core
_1`'.'`t1’`/,/COMMIT/p' > /var/mysql/data/delete.txt
2
将delete.txt中的记录转换为SQL语句
cat delete.txt | sed -n '/###/p' | sed 's/### //g;s/\/\*.*/,/g;s/DELETE FROM/INSERT INTO/g;s/WHERE/SELECT/g;' | sed -r 's/(@4.*),/\1;/g' | sed 's/@[1-9]=//g' > source.sql
# 7.3.1 通过时间点恢复
mysqlbinlog --stop-datetime="2021-11-03 17:45:52" mysql-bin.000027|mysql -uroot -p
# 7.3.2 通过binlog位置恢复
show binary logs; show binlog events in 'mysql-bin.000028';
mysqlbinlog --stop-position=539 mysql-bin.000028 |mysql -uroot -p
# 8. mysql服务存储引擎
MyISAM和InnoDB
autocommit | ON 开启自动提交 rollback 回滚事务 commit 提交事务
MyISAM 不支持事务,表级锁定,读写互相阻塞,只会缓存索引 读取速度较快,占用资源相对少 不支持外键约束,但支持全文索引
InnoDb引擎 支持事务,行级锁定,读写阻塞与事务隔离级别相关 具有非常高效的缓存特性;能缓存索引,也能缓存数据 整个表和主键以cluster方式存储 所有secondary index 都会保存主键信息 支持分区,表空间,类似oracle数据库 支持外键约束 对硬件资源要求相对比较高
MyISAM 引擎调优 1、设置合适的索引 2、调整读写优先级,根据实际需求确保重要操作更优先执行 3、启动延迟插入改善大批量写入性能 4、尽量顺序操作让insert数据都写入到尾部,减少阻塞 5、分解大的时间长的操作,降低单个操作的阻塞时间 6、降低并发数 7、充分利用query cache 或者memcached缓存服务可以极大的提高访问效率
innodb引擎调优 1、主键尽可能小,避免给secondary index带来过大的空间负担 2、避免全表扫描,因为会使用表锁 3、尽可能缓存所有的索引和数据,提高响应速度,减少磁盘IO消耗 4、在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交 5、合理设置innodb配置参数 6、避免主键更新,因为会带来大量的数据移动
查看支持的引擎 show engines\G;
更改mysql引擎 ALTER TABLE oldboy ENGINE = MyISAM;
使用sed对备份内容进行引擎转换 mysqldump >all.sql 利用sed替换引擎
转换引擎工具 mysql_convert_table_format --host=$HOSTNAME --user=$USERNAME --password=$PASSWD --socket=$SOCKETPATH --type=$TBTYPE $DBNAME $TBNAME
mysql_convert_table_formart 命令 mysql_convert_table_formart --user=root --password= --engine=MyISAM oldboy t2
查询引擎 show create table test;
网站打开慢 top查询进程和负载 show full processlist; 慢查询语句 long_query_time = 1 log-slow-queries = /data/3306/slow.log
# 9. 数据库安全管理思想
# 9.1 项目开发制度流程
办公开发环境---办公测试环境---IDC测试环境---正式环境
# 9.2 各种操作申请流程
1、开发等人员权限申请流程
2、数据库更新执行流程
3、烂SQL语句计入KPI考核
# 9.3 定期对内部人员培训
1、数据库设计规范及制度
2、SQL语句执行优化,性能优化技巧等。
3、数据库架构设计等内容
# 9.4 账户权限控制
1、权限申请流程要设置规范、合理
2、测试环境可以开放权限,正式环境要严格控制写权限
3、权限分配规划
4、特殊人员,如领导,需要权限时,我们要问清楚他做什么,发邮件回复,注明权限范围,多提醒操作注意事项
5、特权账号,由DBA控制,禁止在任何客户端上执行特权账号操作
# 9.5 web账户授权实战案例
a.生产环境主库用户的账号授权:
GRANT SELECT,INSERT,UPDATE,DELETE ON blog.*TO 'blog'@10.0.0.%' identified by 'oldboy456';
b.生产环境从库用户的授权:
GRANT SELECT ON blog.*TO 'blog'@'10.0.0.%'identified by 'oldboy456';
当然从库除了做SELECT 的授权外,还可以加read-only等只读参数。
2.4产环境读写分离账户设置
给开发人员的读写分离用户设置,除了IP必须要不同外,我们尽量为开发人员使用提供方便。因此,读写分离的地址,除了IP不同外,账号,密码,端口等看起来都是一样的,这才是人性化的设计,体现了运维或DBA人员的专业。
主库(尽量提供写服务):blog oldboy456 ip:10.0.0.179 port 3306
从库(今提供读服务): blog oldboy456 ip:10.0.0.180 port 3306
提示: 两个账号的权限是不一样的
提示:从数据库的设计上,对于读库,开发人员应该设计优先连接读库,如果读库没有,超时后,可以考虑主库,从程序设计上来保证提升用也要根据主库的繁忙程度来综合体验,具体情况都是根据业务项目需求来抉择
# 9.6 数据库客户端访问控制
1.更改默认mysql client 端口,如phpadmin 管理端口为9999,其他客户端也是一样的
2:数据库web client端统一部署在1-2台不对外服务Server上,限制ip,及9999端口只能从内网访问。
3.不做公网域名解析,用host实现访问或者内部IP
4phpadmin站点目录独立所有其他站点根目录外,只能由指定的域名或ip地址访问。
5.限制使用web连接的账号管理数据库,根据用户角色设置指定账号访问。
6按开发及相关人员根据职位角色分配管理账号
7:设置指定账号访问(apache/nginx验证+mysql用户两个登录限制)
8.统一所有数据库账号登录入口地址。禁止所有开发私自上传phpadmin等数据库管理等
9开通vpn,跳板机,内部IP管理数据库
系统层控制
1限制或禁止开发人员ssh root 管理,通过sudo细化权限,使用日志审计
2对phpadmin端config等配置文件进行读写权限控制
3:取消费指定服务器的所有phpadmin web 连接端
4.禁止非管理人员管理有数据库web client端的服务器的权限。
5读库分业务读写分离
细则补充:对数据库的select 等大量测试,统计,备份等操作,要在不对外提供select的单独从库执行
主从架构生产环境从服务器分业务拆分使用案例:
M-->s1==对外部用户提供服务(浏览帖子,浏览博客,浏览文章)
-->s2==>对外部用户提供服务(浏览帖子,浏览博客,浏览文章)
-->s3==>对外部用户提供服务(浏览帖子,浏览博客,浏览文章)
-->s2==>对内部用户提供服务(后台访问,脚本任务,数据分析,开发人员浏览)
-->s5==>数据库备份服务(开启从服务器binlog功能,可实现增量备份及恢复)
# 10. 索引优化
# 10.1 MySQL索引原理
索引目的
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者ze开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
索引原理
除了词典,生活中随处可见索引的例子,如火车站的车次表、图书的目录等。它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂许多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段……这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的,数据库实现比较复杂,数据保存在磁盘上,而为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
磁盘IO与预读
前面提到了访问磁盘,那么这里先简单介绍一下磁盘IO和预读,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
# 10.2 慢查询优化
关于MySQL索引原理是比较枯燥的东西,大家只需要有一个感性的认识,并不需要理解得非常透彻和深入。我们回头来看看一开始我们说的慢查询,了解完索引原理之后,大家是不是有什么想法呢?先总结一下索引的几大基本原则: 建索引的几大原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
查询优化神器 - explain命令
关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外,下面会讲到)。所以优化语句基本上都是在优化rows。 慢查询优化基本步骤
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析
索引一经创建不能修改,如果要修改索引,只能删除重建。可以使用
DROP INDEX index_name ON table_name;删除索引。
3、索引设计的原则
1)适合索引的列是出现在where子句中的列,或者连接子句中指定的列;
2)基数较小的类,索引效果较差,没有必要在此列建立索引;
3)使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间;
4)不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
查看索引使用情况 SHOW STATUS LIKE 'Handler_read%';
索引优化规则:
1)如果MySQL估计使用索引比全表扫描还慢,则不会使用索引。
返回数据的比例是重要的指标,比例越低越容易命中索引。记住这个范围值——30%,后面所讲的内容都是建立在返回数据的比例在30%以内的基础上。
2)前导模糊查询不能命中索引。
# 11. mysql数据库优化
https://www.toutiao.com/i6633207458275787268 //MySQL单表数据量过千万,采坑优化记录,完美解决方案
https://blog.csdn.net/ctrip_tech/article/details/104681323 //干货 | 100亿+数据量,每天50W+查询,携程酒店数据智能平台实践
# 11.1 硬件优化
CPU,内存,磁盘
SSD>sas>sata
RAID0>RAID10>RAID5>RAID1
网卡 汇聚
# 11.2 参数的优化
优化的幅度很小,大部分是架构以及SQL语句优化
show global status\G
调优工具 mysqlreport
# 11.3 SQL语句的优化
# 11.3.1 索引优化
找出慢的SQL
慢查询日志分析工具
mysqldumpslow,mysqlsla,myprofi,mysql-explain-slow-log,mysqllogfilter
每天晚上0点定时分析慢查询,发到核心开发,DBA分析,及高级运维,CTO的邮箱
DBA分析给出优化建议————核心开发确认————DBA线上操作处理
# 11.3.2 大的复杂的SQL语句拆分成多个小的SQL语句
# 11.3.3 数据库是存储数据的地方,不是计算数据的地方
# 11.4 架构的优化
a.业务拆分 搜索功能 like '%淘宝%' 这种不要用mysql
b.数据库前端必须加缓存,如redis和memcached
c.某些业务应用合用nosql持久化存储,例如memcache,redis
d.动态数据静态化,整个文件静态化,页面片段静态化。
e.数据库集群与读写分离。 一主多从,多主多从。通过程序或者中间件进行集群读写分离
单表超过2000万,拆库拆表
# 11.5 流程、制度、安全优化
任何一次人为数据库记录的更新,都要走一个流程:
a.人的流程:开发-->核心开发-->运维或DBA↓ b.测试流程:内网测试-->IDC测试-->线上执行↓c.客户端管理, PHPMYADMIN。↓
# 11.6 软件优化
操作系统 64位 软件 mysql 源码和二进制安装,编译优化
配置phpmyadmin 网页配置文件在 /etc/httpd/conf.d/phpMyAdmin.conf 设置多实例登录 \libraries\config.default.php $cfg['AllowArbitraryServer'] = true;开启
$hosts = array( '1'=>array('host'=>'192.168.0.200','user'=>'phpmyadmin','password'=>'phpmyadmin','port'=>3307), '2'=>array('host'=>'192.168.0.200','user'=>'phpmyadmin','password'=>'phpmyadmin','port'=>3308) );
sed -n '/^-- Current Database: wordpress/,/^-- Current Database: `/p' all_2020-09-04.sql >wordpress.sql &
# 11.7 常见MySQl压力测试工具
mysqlslap
Sysbench:功能强大,官网: https://github.com/akopytov/sysbench
tpcc-mysql
MySQL Benchmark Suite
MySQL super-smack
MyBench
# 12.数据库开发规范
1. 数据库对象命名规范
数据库对象
命名规范的对象是指数据库SCHEMA、表TABLE、索引INDEX、约束CONSTRAINTS等的命名约定
数据库对象命名原则
- 命名使用具有意义的英文词汇,词汇中间以下划线分隔
- 命名只能使用英文字母、数字、下划线
- 避免用MySQL的保留字如:call、group等
- 所有数据库对象使用小写字母
数据库命名规范
- 数据库名不能超过30个字符
- 数据库命名必须为项目英文名称或有意义的简写
- 数据库创建时必须添加默认字符集和校对规则子句。默认字符集为UTF8(已迁移dumbo的使用utf8mb4)
- 命名应使用小写
表命名规范
- 同一个模块的表尽可能使用相同的前缀,表名称尽可能表达含义
- 多个单词以下划线(_)分隔
- 表名不能超过30个字符
- 普通表名以t_开头,表示为table,命名规则为t_模块名(或有意义的简写)_+table_name
- 临时表(运营、开发或数据库人员临时用作临时进行数据采集用的中间表)命名规则:加上tmp前缀和8位时间后缀(tmp_test_user_20181109)
- 备份表(DBA备份用作保存历史数据的中间表)命名规则:加上bak前缀和8位时间后缀(bak_test_user_20181109)
- 命名应使用小写
字段命名规范
- 字段命名需要表示其实际含义的英文单词或简写,单词之间用下划线(_)进行连接
- 各表之间相同意义的字段必须同名
- 字段名不能超过30个字符
用户命名规范
- 生产使用的用户命名格式为 code_应用
- 只读用户命名规则为 read_应用
2. 数据库对象设计规范
存储引擎的选择
如无特殊需求,必须使用innodb存储引擎
字符集的选择
如无特殊要求,必须使用utf8或utf8mb4
表设计规范
- 不同应用间所对应的数据库表之间的关联应尽可能减少,不允许使用外键对表之间进行关联,确保组件对应的表之间的独立性,为系统或表结构的重构提供可能性
- 表设计的角度不应该针对整个系统进行数据库设计,而应该根据系统架构中组件划分,针对每个组件所处理的业务进行数据库设计
- 表必须要有PK
- 一个字段只表示一个含义
- 表不应该有重复列
- 禁止使用复杂数据类型(数组,自定义等)
- 需要join的字段(连接键),数据类型必须保持绝对一致,避免隐式转换
- 设计应至少满足第三范式,尽量减少数据冗余。一些特殊场景允许反范式化设计,但在项目评审时需要对冗余字段的设计给出解释
- TEXT字段必须放在独立的表中,用PK与主表关联。如无特殊需要,禁止使用TEXT、BLOB字段
- 需要定期删除(或者转移)过期数据的表,通过分表解决
- 单表字段数不要太多,建议最多不要大于50个
- MySQL在处理大表时,性能就开始明显降低,所以建议单表物理大小限制在16GB,表中数据控制在2000W内
- 如果数据量或数据增长在前期规划时就较大,那么在设计评审时就应加入分表策略
- 无特殊需求,严禁使用分区表
字段设计规范
- INT:如无特殊需要,存放整型数字使用UNSIGNED INT型。整型字段后的数字代表显示长度
- DATETIME:所有需要精确到时间(时分秒)的字段均使用DATETIME,不要使用TIMESTAMP类型
- VARCHAR:所有动态长度字符串 全部使用VARCHAR类型,类似于状态等有限类别的字段,也使用可以比较明显表示出实际意义的字符串,而不应该使用INT之类的数字来代替;VARCHAR(N),N表示的是字符数而不是字节数。比如VARCHAR(255),可以最大可存储255个字符(字符包括英文字母,汉字,特殊字符等)。但N应尽可能小,因为MySQL一个表中所有的VARCHAR字段最大长度是65535个字节,且存储字符个数由所选字符集决定。如UTF8存储一个字符最大要3个字节,那么varchar在存放占用3个字节长度的字符时不应超过21845个字符。同时,在进行排序和创建临时表一类的内存操作时,会使用N的长度申请内存。(如无特殊需要,原则上单个varchar型字段不允许超过255个字符)
- TEXT:仅仅当字符数量可能超过20000个的时候,才可以使用TEXT类型来存放字符类数据,因为所有MySQL数据库都会使用UTF8字符集。所有使用TEXT类型的字段必须和原表进行分拆,与原表主键单独组成另外一个表进行存放。如无特殊需要,严禁开发人员使用MEDIUMTEXT、TEXT、LONGTEXT类型
- 对于精确浮点型数据存储,需要使用DECIMAL,严禁使用FLOAT和DOUBLE
- 如无特殊需要,严禁开发人员使用BLOB类型
- 如无特殊需要,字段建议使用NOT NULL属性,可用默认值代替NULL
- 自增字段类型必须是整型且必须为UNSIGNED,推荐类型为INT或BIGINT,并且自增字段必须是主键或者主键的一部分
索引设计规范
- 索引必须创建在索引选择性选择性较高的列上,选择性的计算方式为: select count(distinct(col_name))/count(*) from tb_name;如果结果小于0.2,则不建议在此列上创建索引,否则大概率会拖慢SQL执行
- 组合索引的首字段,必须在where条件中,对于确定需要组成组合索引的多个字段,建议将选择性高的字段靠前放
- 禁止使用外键
- Text类型字段如果需要创建索引,必须使用前缀索引
- 单张表的索引数量理论上应控制在5个以内。经常有大批量插入、更新操作表,应尽量少建索引
- ORDER BY,GROUP BY,DISTINCT的字段需要添加在索引的后面,形成覆盖索引
- 尽量使用Btree索引,不要使用其它类型索引
约束设计规范
- PK应该是有序并且无意义的,尽量由开发人员自定义,且尽可能短,使用自增序列。
- 表中除PK以外,还存在唯一性约束的,可以在数据库中创建以“uidx_”作为前缀的唯一约束索引。
- PK字段不允许更新。
- 禁止创建外键约束,外键约束由应用控制。
- 如无特殊需要,所有字段必须添加非空约束,即not null。
- 如无特殊需要,所有字段必须有默认值。
SQL编写规范
- 尽量避免使用select *,join语句使用select *可能导致只需要访问索引即可完成的查询需要回表取数
- 严禁使用select * from table而不加任何where条件
- MySQL中的text类型字段存储的时候不是和由其他普通字段类型的字段组成的记录存放在一起,而且读取效率本身也不如普通字段块。如果不需要取回text字段,又使用了select *,会让完成相同功能的sql所消耗的io量大很多,而且增加部分的io效率也更低下
- 在取出字段上可以使用相关函数,但应尽可能避免出现now(),rand(),sysdate(),current_user()等不确定结果的函数,在Where条件中的过滤条件字段上严禁使用任何函数,包括数据类型转换函数
- 所有连接的SQL必须使用Join ... On ...方式进行连接,而不允许直接通过普通的Where条件关联方式。外连接的SQL语句,可以使用Left Join On的Join方式,且所有外连接一律写成Left Join,而不要使用Right Join
- 分页查询语句全部都需要带有排序条件,除非应用方明确要求不要使用任何排序来随机展示数据
- WHERE条件中严禁在索引列上进行数学运算或函数运算
- 用in()/union替换or,并注意in的个数小于300
- 严禁使用%前缀进行模糊前缀查询:如:select id,val from table where val like ‘%name’;可以使用%模糊后缀查询如:select id,val from table where val like ‘name%’
- 严禁使用INSERT ON DUPLICATE KEY UPDATE、REPLACE INTO、INSERT IGNORE
# 13.Mysql数据库安全权限控制管理思想
# 1 制度与流程控制
# 1.1 项目开发制度流程
办公开发环境--->办公测试环境--->IDC测试环境--->ID 正式环境。通过这种较完善的项目开发制度及流程控制,尽可能的防止潜在的问题隐患发生。
办公开发环境--->办公测试环境--->IDC测试环境—-->IDC正式环境。通过这种较完善的项目开发制度及流程控制,尽可能的防止潜在的问题隐患发生。
# 1.2 数据库更新流程。
开发人员提交需求--->开发主管审核--->部门领导审核--->DBA(运维)审核--->DBA(运维)执行项目开发制度及流程控制的数据库更新步骤(每个步骤都要测试),最后在IDC正式环境执行。
需要说明的是,在开发人员一开始提交需求时,就可以同时抄给以上的领导及审核人员,然后,审核人员依次审核。对于特殊紧急需求,可以根据紧急程度特殊处理,这里可以制定个紧急需求处理流程,比如:开发人员提交需求--->DBA(运维)审核,然后操作完在汇报给其它审核人员。 通过完善的数据库更新流程控制,可以防止很多潜在的数据丢失、破坏等问题发生。
# 1.3 DBA参与项目数据库设计
在项目开发环节上,DBA或资深运维人员最好参与数据库设计与审核工作,这样可以从源头上减少降低不良的数据库设计及不良SQL语句的发生,还可以做所有语句的审核工作,包括select,但这个需要评估工作量是否允许,一般的互联网公司实施全审核比较困难。
# 1.4 各种操作申请流程,
1)开发等人员权限申请流程。 2)数据库更新执行流程。 3)烂SQL语句计入KPI考核。
# 1.5 定期对内部人员培训
定期给开发及相关人员培训,目的还是从源头上降低不良数据库设计及不良SQL语句的发生,并通过培训让大家知晓大家数据库性能的重要性,让他大家提升开发时照顾数据库性能的意识。 1)数据库设计规范及制度。 2) SQL语句执行优化,性能优化技巧等。 3)数据库架构设计等内容。
# 2 账户权限控制.
# 2.1 内部开发等人员权限分配
1)权限申请流程要设置规范、合理,让需求不明确者知难而退(比如老男孩老师的曾经公司开发就有上百人) 2)办公开发和测试环境可以放开权限,idc测试和正式环境要严格控制数据库写权限,并且读权限和对外业务服务分离。 3)开发人员正式环境数据库权限分配规则:给单独的不对外服务的正式从库只读权限,不能分配线上正式主库写权限。 4)特殊人员(如领导),需要权限时,我们要问清楚他做什么,发邮件回复,注明用户名、密码、权限范围,多提醒操作注意事项,如果有可能由DBA人员代替其操作。 5)特权帐号(allprivliges),由DBA控制,禁止在任何客户端上执行特权账号操作(如只能localhost或其他策略)。
# 2.2 web 账户权限分配制度
1)写库账号默认权限为select, insert,update,delete。不要给建表改表(create,alter)等的权限,更不能all权限。 2)读库帐号默认权限为select(配合mysqlread-only参数用)。确保从库对所有非super权限是只读的。 3)最好专库专账号,不要一个账号管理多个库。碎库特别多的小公司根据情况特殊对待处理。 4)如果是lamp,lnmp一体在一台服务器的环境,db权限主机要设置为localhost,避免用root用户作为web连接用。
# 3 数据库运维管理思想核心
1)未雨绸缪,不要停留在制度上,而是,实际做出来。 2)亡羊补牢,举一反三,切记,不能好了伤疤忘了疼。 3)完备的架构设计及备份、恢复策略。。 4)定期思考、并实战模拟以上策略演练。·
未雨绸缪永远比出了问题在处理要好的多,出了问题补救是没办法不得已的事,最差的是很多公司,没有亡羊补牢,而是好了伤疤忘了疼,没过多久问题又发生了。
因此,在工作中要尽量做到未雨绸缪,从源头上减少故障的发生。其次,要做到亡羊补牢、举一反三,事情出现一次就不能在出现第二次。当然,完善的备份和恢复策略也是需要做的。只有把这些结合起来,才能把我们运维的工作做的更好。
web账户授权实战案例a.生产环境主库用户的账号授权:GRANT SELECT,INSERT,UPDATE,DELETE ON blog.*TO
web账户授权实战案例
a.生产环境主库用户的账号授权:
GRANT SELECT,INSERT,UPDATE,DELETE ON blog.*TO 'blog'@10.0.0.%' identified by 'oldboy456';
b.生产环境从库用户的授权:
GRANT SELECT ON blog.*TO 'blog'@'10.0.0.%'identified by 'oldboy456';
当然从库除了做SELECT 的授权外,,还可以加read-only等只读参数。
2.4产环境读写分离账户设置
给开发人员的读写分离用户设置,除了IP必须要不同外,我们尽量为开发人员使用提供方便。因此,读写分离的地址,除了IP不同外,账号,密码,端口等看起来都是一样的,这才是人性化的设计,体现了运维或DBA人员的专业。
主库(尽量提供写服务):blog oldboy456 ip:10.0.0.179 port 3306
从库(今提供读服务): blog oldboy456 ip:10.0.0.180 port 3306
提示: 两个账号的权限是不一样的
提示:从数据库的设计上,对于读库,开发人员应该设计优先连接读库,如果读库没有,超时后,可以考虑主库,从程序设计上来保证提升用也要根据主库的繁忙程度来综合体验,具体情况都是根据业务项目需求来抉择
3,数据库客户端访问控制
1.更改默认mysql client 端口,如phpadmin 管理端口为9999,其他客户端也是一样的
2:数据库web client端统一部署在1-2台不对外服务Server上,限制ip,及9999端口只能从内网访问。
3.不做公网域名解析,用host实现访问或者内部IP
4phpadmin站点目录独立所有其他站点根目录外,只能由指定的域名或ip地址访问。
5.限制使用web连接的账号管理数据库,根据用户角色设置指定账号访问。
6按开发及相关人员根据职位角色分配管理账号
7:设置指定账号访问(apache/nginx验证+mysql用户两个登录限制)
8.统一所有数据库账号登录入口地址。禁止所有开发私自上传phpadmin等数据库管理等
9开通vpn,跳板机,内部IP管理数据库
系统层控制
1限制或禁止开发人员ssh root 管理,通过sudo细化权限,使用日志审计
2对phpadmin端config等配置文件进行读写权限控制
3:取消费指定服务器的所有phpadmin web 连接端
4.禁止非管理人员管理有数据库web client端的服务器的权限。
5读库分业务读写分离
细则补充:对数据库的select 等大量测试,统计,备份等操作,要在不对外提供select的单独从库执行
主从架构生产环境从服务器分业务拆分使用案例:
M-->s1==对外部用户提供服务(浏览帖子,浏览博客,浏览文章)
-->s2==>对外部用户提供服务(浏览帖子,浏览博客,浏览文章)
-->s3==>对外部用户提供服务(浏览帖子,浏览博客,浏览文章)
-->s2==>对内部用户提供服务(后台访问,脚本任务,数据分析,开发人员浏览)
-->s5==>数据库备份服务(开启从服务器binlog功能,可实现增量备份及恢复)