 shell编程
shell编程
# 端打印、算术运算、常用变量
#!称为 shebang (opens new window)
cmd1 ; cmd2执行cmd1后在执行cmd2
# 终端打印
# echo
echo hello world
echo 'hello world'
echo "hello world"
2
3
bash不会对单引号内变量(如$var)求值。
# printf
printf "hello world"
#!/bin/bash
printf "%-5s %-10s %-4s\n" NO Name Mark
printf "%-5s %-10s %-4.2f\n" 01 Tom 90.3456
printf "%-5s %-10s %-4.2f\n" 02 Jack 89.2345
printf "%-5s %-10s %-4.2f\n" 03 Jeff 98.4323
2
3
4
5
6
7
- %-5s 格式为左对齐且宽度为5的字符串代替(-表示左对齐),不使用则是又对齐。
- %-4.2f 格式为左对齐宽度为4,保留两位小数。
格式替代符
- %b 相对应的参数被视为含有要被处理的转义序列之字符串。
- %c ASCII字符。显示相对应参数的第一个字符
- %d, %i 十进制整数
- %e, %E, %f 浮点格式
- %g %e或%f转换,看哪一个较短,则删除结尾的零
- %G %E或%f转换,看哪一个较短,则删除结尾的零
- %o 不带正负号的八进制值
- %s 字符串
- %u 不带正负号的十进制值
- %x 不带正负号的十六进制值,使用a至f表示10至15
- %X 不带正负号的十六进制值,使用A至F表示10至15
- %% 字面意义的%
转义序列
- \a 警告字符,通常为ASCII的BEL字符
- \b 后退
- \c 抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略
- \f 换页(formfeed)
- \n 换行
- \r 回车(Carriage return)
- \t 水平制表符
- \v 垂直制表符
- \ 一个字面上的反斜杠字符
- \ddd 表示1到3位数八进制值的字符,仅在格式字符串中有效
- \0ddd 表示1到3位的八进制值字符
# 在echo中转义换行符
echo -e "包含转义序列的字符串"
echo -e "1\t2\t3"
1 2 3
2
3
# 打印彩色输出
文字色
echo -e "\e[1;31mThis is red text\e[0m"
This is red text
2
- \e[1;31m 将颜色设置为红色
- \e[0m 将颜色重新置回
颜色码:重置=0,黑色=30,红色=31,绿色=32,黄色=33,蓝色=34,洋红=35,青色=36,白色=37
背景色
echo -e "\e[1;42mGreed Background\e[0m"
Greed Background
2
颜色码:重置=0,黑色=40,红色=41,绿色=42,黄色=43,蓝色=44,洋红=45,青色=46,白色=47
文字闪动
echo -e "\033[37;31;5mMySQL Server Stop...\033[39;49;0m"
红色数字处还有其他数字参数:0 关闭所有属性、1 设置高亮度(加粗)、4 下划线、5 闪烁、7 反显、8 消隐
# 算术运算
# 整数运算
#!/bin/bash
no1=2;
no2=3;
let result=no1+no2
echo $result
2
3
4
5
- 自加操作
let no++ - 自减操作
let no-- - 简写形式
let no+=10let no-=20分别等同于let no=no+10let no=no-20
操作符[]运算方法
#!/bin/bash
no1=2;
no2=3;
result=$[$no1+no2]
echo $result
2
3
4
5
使用方法和let相似,在[]中可以使$前缀。
(())运算方法
#!/bin/bash
no1=2;
no2=3;
result=$((no1+no2))
echo $result
2
3
4
5
result=`expr 2 + 3`
result=$(expr $no1 + 5)
2
expr的常用运算符
- 加法运算:+
- 减法运算:-
- 乘法运算:*
- 除法运算:/
- 求摸(取余)运算:%
# 精密计算
算术操作高级运算工具:bc (opens new window),它可以执行浮点运算和一些高级函数
echo "1.212*3" | bc
3.636
2
设定小数精度(数值范围)
echo "scale=2;3/8" | bc
0.37
2
参数scale=2是将bc输出结果的小数位设置为2位。
进制转换
#!/bin/bash
abc=192
echo "obase=2;$abc" | bc
2
3
执行结果为:11000000,这是用bc将十进制转换成二进制。
#!/bin/bash
abc=11000000
echo "obase=10;ibase=2;$abc" | bc
2
3
执行结果为:192,这是用bc将二进制转换为十进制。
计算平方和平方根
echo "10^10" | bc
echo "sqrt(100)" | bc
2
# 常用变量
结合不同的引导为变量赋值
- 双引号 "" :允许通过$符号引用其他变量值
- 单引号 '' :禁止引用其他变量值,$视为普通字符
- 反撇号 `` :将命令执行的结果输出给变量
# 用户自定义变量
设置变量的作用范围
格式:
export 变量名...
export 变量名=变量值 [...变量名n=变量值n]
2
清除用户自定义变量
格式:
unset 变量名
# 环境变量
环境变量配置文件
- 全局配置文件:/etc/profile
- 用户配置文件:~/.bash_profile
查看环境变量
set (opens new window)命令可以查看所有的shell (opens new window)变量,其中包括环境变量
常见的环境变量
- $USER 查看账户信息
- $logname (opens new window) 登录相关信息
- $UID
- $Shell (opens new window)
- $HOME 家目录
- $pwd (opens new window)
- $PATH 用户所输入的命令是在哪些目录中查找
- $PS1
- $PS2
- $RANDOM 随机数
# 位置变量
表示为:$n (n为1~9之间的数字)
#./test.sh one two three four five six
- $0 表示文件名本身
- one就是:$1
- two就是:$2
# 预定义变量
- $# :命令行中位置参数的个数
- $* :所有位置参数的内容
- $? :上一条命令执行后返回的状态,当返回状态值为0时表示执行正常,非0表示执行异常或出错
- $$ :当前所在进程的进程号
- $! :后台运行的最后一个进程号
- $0 :当前执行的进程/程序名
# 文件的描述符和重定向
文件描述符是和文件的输入、输出相关联的非负整数,Linux内核(kernel)利用文件描述符(file (opens new window) descriptor)来访问文件。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。常见的文件描述符是stdin、stdout和stderr。
# 系统预留文件描述符
- 0 —— stdin(标准输入)
- 1 —— stdout(标准输出)
- 2 —— stderr(标准错误)
重定向将输入文本通过截取模式保存到文件:
echo "this is a text line one" > test.txt
写入到文件之前,文件内容首先会被清空。
重定向将输入文本通过追加模式保存到文件:
echo "this is a text line one" >> test.txt
写入到文件之后,会追加到文件结尾。
标准错误输出:
[root@localhost text]# cat linuxde.net
cat: linuxde.net: No such file or directory
2
标准错误输出的重定向方法:
方法一:
[root@localhost text]# cat linuxde.net 2> out.txt //没有任何错误提示,正常运行。
方法二:
[root@localhost text]# cat linuxde.net &> out.txt
2
3
4
因为错误信息被保存到了out.txt文件中。
[root@localhost text]# cat linuxde.net 2> /dev/null
将错误输出丢弃到/dev/null中,/dev/null是一个特殊的设备文件,这个文件接受到任何数据都会被丢系,通常被称为位桶、黑洞。
# tee命令
tee命令可以将数据重定向到文件,另一方面还可以提供一份重定向数据的副本作为后续命令的stdin。
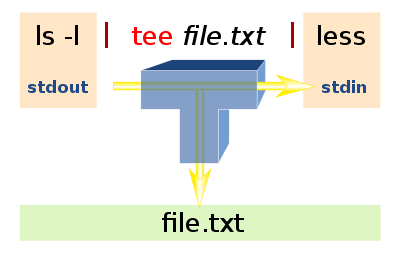
在终端打印stdout同时重定向到文件中:
ls | tee out.txt
1.sh
1.txt
2.txt
eee.tst
EEE.tst
one
out.txt
string2
www.pdf
WWW.pdf
WWW.pef
[root@localhost text]# ls | tee out.txt | cat -n
1 1.sh
2 1.txt
3 2.txt
4 eee.tst
5 EEE.tst
6 one
7 out.txt
8 string2
9 www.pdf
10 WWW.pdf
11 WWW.pef
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 重定向脚本内的文本片段(多行文本)
#!/bin/bash
cat <<EOF>text.log
this is a text line1
this is a text line2
this is a text line3
EOF
2
3
4
5
6
在cat <<EOF>text.log与下一个EOF行之间的所有文本都会当作stdin数据输入到text.log中。
# 自定义文件描述符
除了0、1和2分别是stdin、stdout和stderr的系统预留描述符,我们还可以使用exec命令创建自定义文件描述符,文件的的打开模式有只读模式、截断模式和追加模式。
< 操作符用于从文件中读取至stdin:
echo this is a test line > input.txt
exec 3<input.txt //自定义文件描述符3打开并读取文件
2
在命令中使用文件描述符3:
cat <&3
this is a test line
2
这里需要注意只能读取一次,如果再次使用需要重新创建文件描述符。
> 操作符用于截断模式的文件写入(数据在文件内容被截断之后写入):
exec 4>output.txt
echo this is a new line >&4
cat output.txt
this is a new line
2
3
4
>> 操作符用于追加模式的文件写入(添加数据到文件中,原有数据不会丢失):
exec 5>>output.txt
echo this is a appended line >&5
cat output.txt
this is a new line
this is a appended lin
2
3
4
5
# 数组、关联数组和别名使用
数组作为一种特殊的数据结构在任何一种编程语言中都有它的一席之地,数组在Shell脚本中也是非常重要的组成部分,它借助索引将多个独立的数据存储为一个集合。
# 数组
普通数组只能使用整数作为数组的索引值。
定义数组
格式:array[key]=value
单行一列值:
array_pt=( 1 2 3 4 5 6 )
一组索引值:
array_pt[0]="text1"
array_pt[1]="text2"
array_pt[2]="text3"
array_pt[3]="text4"
array_pt[4]="text5"
array_pt[5]="text6"
2
3
4
5
6
打印数组
打印指定索引的数组元素内容:
#echo ${array_pt[0]}
text1
index=3
#echo ${array_pt[$index]}
text4
2
3
4
5
打印数组中的所有值:
#echo ${array_pt[*]}
或者
#echo ${array_pt[@]}
2
3
打印数组长度(即数组中元素的个数):
#echo ${#array_pt[*]}
删除数组:
unset array_pt[1] //删除数组中第一个元素
unset array_pt //删除整个数组
2
数组的提取:
例如定义了数组 array=( [0]=one [1]=two [2]=three [3]=four )
${array[@]:0} //除去所有元素
${array[@]:1} //出去第一个元素后的所有元素
#echo ${array[@]:0:2}
one two
#echo ${array[@]:1:2}
two three
2
3
4
5
6
子串删除:
#echo ${array[@]:0}
one two three four
2
左边开始最短的匹配:"t*e",这将匹配到"thre"
#echo ${array[@]#t*e}
one two e four
2
左边开始最长的匹配,这将匹配到"three"
#echo ${array[@]##t*e}
从字符串的结尾开始最短的匹配
#echo ${array[@]%o}
one tw three four
2
从字符串的结尾开始最长的匹配
# echo ${array[@]%%o}
one tw three four
2
子串替换:
#echo ${array[@]/o/m}
mne twm three fmur
2
没有指定替换子串,则删除匹配到的子符
#echo ${array[@]//o/}
ne tw three fur
2
替换字符串前端子串
#echo ${array[@]/#o/k}
kne two three four
2
替换字符串后端子串
#echo ${array[@]/%o/k}
one twk three four
2
# 关联数组
关联数组从bash 4.0开始被引入,关联数组的索引值可以使用任意的文本。关联数组在很多操作中很有用。
关联数组的声明:
declare -A array_var
使用内嵌索引-值列表法将元素添加到关联数组:
array_var=( [one]=one-1 [two]=two-2 [three]=three-3 [four]=four-4 [five]=five-5 [six]=six-6 )
使用独立的索引-值进行赋值:
array_var[one]=one-1
array_var[two]=two-2
array_var[three]=three-3
array_var[four]=four-4
array_var[five]=five-5
array_var[six]=six-6
2
3
4
5
6
关联数组的打印方法跟普通数组用法一样。
列出数组索引值:
#echo ${!array_var[*]}
four one five six two three
2
列出索引值的方法也可以用在普通数组上。
# 别名
别名就是提供一种便捷的方式来完成某些长串命令的操作。省去不必要的麻烦,提高效率。一般可以是函数或者alias命令来实现。
alias举例
alias nginxrestart='/usr/local/webserver/nginx/sbin/nginx -s reload'
这样设置之后以后可以使用nginxrestart这个命令来代替/usr/local/webserver/nginx/sbin/nginx -s reload了。这样设置重启之后就会失效,所以需要将它放入~/.bashrc文件中。
echo 'alias nginxrestart="/usr/local/webserver/nginx/sbin/nginx -s reload"' >> ~/.bashrc
查看系统已经定义的别名
[root@mail text]# alias
alias cp='cp -i'
alias l.='ls -d .* --color=tty'
alias ll='ls -l --color=tty'
alias ls='ls --color=tty'
alias mv='mv -i'
alias rm='rm -i'
alias vi='vim'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
2
3
4
5
6
7
8
9
别名转义
有些命令不是总是希望使用别名,可以在命令之前输入反斜杠\来忽略所定义过的别名。
#\command
# Shell函数的定义、执行、传参和递归函数
Bash(Bourne Again shell)也跟其他编程语言一样也支持函数,一般在编写大型脚本中需要用到,它可以将shell脚本程序划分成一个个功能相对独立的代码块,使代码的模块化更好,结构更加清晰,并可以有效地减少程序的代码量。但是bash作为一种解释性语言,bash 在编程能力方面提供的支持并不像其他编译性的语言(例如 C 语言)那样完善,执行效率也会低很多。
# shell函数的定义、执行与传参
定义
格式1
function name() {
command sequence(命令序列);
}
2
3
格式2
name() {
Command sequence(命令序列);
}
2
3
可以带function name()定义,也可以直接name()定义,不带任何参数。
执行
name;
直接使用函数名称即可调用某个函数。
传递参数
#!/bin/bash
aa="this is aa"
bb="this is bb"
function name() { #定义函数name
local cc="this is cc" #定义局部变量$cc
local dd="this is dd" #定义局部变量$dd
echo $aa, $bb #访问参数1和参数2
echo $cc #打印局部变量
return 0 #shell函数返回值是整形,并且在0~257之间。
}
echo $dd #这里将会打印不生效,因为dd是局部变量。
name #使用函数name
2
3
4
5
6
7
8
9
10
11
12
13
上例中:
- aa 和 bb 定义的是全局变量。
- cc 和 dd 定义的是局部变量,只能在函数 name 中使用。
$aa是第一个参数$1,$bb是第一个参数$2,以此类推$n是第n个参数$n。return 0参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果作为返回值。
# 递归函数
bash也支持递归函数(能够调用自身的函数)例如:
#!/bin/bash
function name() {
echo $1
name hello
sleep 1
}
name
2
3
4
5
6
7
8
运行此脚本后不断打印出hello,按Ctrl+C结束。
递归经典:fork 炸弹
可能很多人都曾经听说过 fork 炸弹,它实际上只是一个非常简单的递归程序,程序所做的事情只有一样:这个递归函数能够调用自身,不算的生成新的进程,这会导致这个简单的程序迅速耗尽系统里面的所有资源,造成拒绝服务攻击。
.()
{
.|.&
}
;
.
2
3
4
5
6
- 第 1 行说明下面要定义一个函数,函数名为小数点,没有可选参数。
- 第 2 行表示函数体开始。
- 第 3 行是函数体真正要做的事情,首先它递归调用本函数,然后利用管道调用一个新进程(它要做的事情也是递归调用本函数),并将其放到后台执行。
- 第 4 行表示函数体结束。
- 第 5 行并不会执行什么操作,在命令行中用来分隔两个命令用。从总体来看,它表明这段程序包含两个部分,首先定义了一个函数,然后调用这个函数。
- 第 6 行表示调用本函数。
# 条件测试操作与流程控制语句
在编写Shell脚本时候,经常需要判断两个字符串是否相等,检查文件状态或者是数字的测试等。Shell提供了对字符串、文件、数值等内容的条件测试以及逻辑流程控制。
# 条件测试操作
程序中的流程控制是由比较和测试语句来处理的,bash具备多种与UNIX系统级特性相兼容的执行测试方法。
# 常用测试操作
test命令,测试特定的表达式是否成立,当条件成立时,命令执行后的返回值为0,否则为其他数值。
格式1
test 条件表达式
格式2
[ 条件表达式 ] //常用格式,使用方括号时,要注意在条件两边加上空格。
2
3
4
常见测试类型
- 测试文件状态
- 字符串的比较
- 整数值的比较
- 逻辑测试
# 测试文件
| 常用的文件测试操作符 | 说明 |
|---|---|
| -d 文件,d的全称是directory | 文件存在且为目录则为真 |
| -f 文件,f的全称是file | 文件存在且为普通文件则为真 |
| -e 文件,e的全称是exist | 文件存在则为真,-e不辨别是文件还是目录 |
| -r 文件,r的全称是read | 文件存在且可读,则为真 |
| -s 文件,s的全称是size | 文件存在且文件大小不为0,则为真 |
| -w 文件,w的全称是write | 文件存在且可写,则为真 |
| -x 文件,x的全称是executable | 文件存在且可执行,则为真 |
| -L 文件,L的全称是Link | 文件存在且为链接文件,则为真 |
| f1 -nt f2,nt的全称是newer than | 文件f1比文件f2新,则为真;根据文件修改时间对比 |
| f1 -ot f2,nt的全称是older than | 文件f1比文件f2旧,则为真;根据文件修改时间对比 |
如果需要获取更多信息,则使用man test
操作符:
- -d:测试是否为目录,是则为真(Directory)
- -e:测试目录或文件是否存在,存在则为真(Exist)
- -f:测试是否为文件,是则为真(file (opens new window))
- -r:测试当前用户是否有权限读取,是则为真(read (opens new window))
- -w (opens new window):测试当前用户是否有权限写入,是这为真(write (opens new window))
- -x:测试当前用户是否可执行该文件,可执行则为真(Excute)
- -L:测试是否为符号链接文件,是则为真(Link)
- -nt:file1 -nt file2 如果 file1 比 file2 新(修改时间),则为真
- -ot:file1 -ot file2 如果 file1 比 file2 旧(修改时间),则为真
# 字符串比较
格式
[ 字符串1 = 字符串2 ]
[ 字符串1 != 字符串2 ]
[ -z 字符串 ]
2
3
4
操作符:
- =:字符串内容相同则为真,就是说包含的文本一摸一样。
- !=:字符串内容不同,则为真(!号表示相反的意思)
- -z:字符串内容为空(长度为零)则为真
- -n:字符串内容非空(长度非零)则为真
- <:string1 < string2 如果string1在本地的字典序列中排在string2之前,则为真
- >:string2 如果string1在本地的字典序列中排在string2之后,则为真
注意点:
1、字符串的 “等于” 比较,为了与POSIX (opens new window)一致,在[]中使用=,(尽管==也可以可以用的)
2、注意在=前后各有一个空格,如果没有空格就是赋值的关系,不是比较的关系。
3、字符串的> <比较运算符,一般放在[[ ]]之中,而不是test ("[]")
4、字符串的> <比较的结果,与本地的locale有关,是按照其字典序列进行比较的
# 整数值比较
格式
[ 整数1 操作符 整数2 ]
2
- -eq:等于(equal)
- -ne:不等于(not equal)
- -gt:大于(Greater than)
- -lt:小于(lesser than)
- -le:小于等于(lesser or equal)
- -ge:大于等于(Greater or equal)
# 逻辑测试
格式
[ 表达式1 ] 操作符 [ 表达式2 ] ...
2
操作符
- -a 或 && :逻辑与,“而且”的意思,前后两个表达式都成立时整个测试结果才为真,否则为假
- -o 或 || : 逻辑或,“或者”的意思,操作符两边至少一个为真时,结果为真,否为为假
- ! :逻辑否,当制定条件不成立时,返回结果为真
# 流程控制语句
Shell有一套自己的流程控制语句,其中包括条件语句、循环语句、选择语句等。
# if条件语句
if 单分支:当“条件成立”时执行相应的操作。
if 条件测试操作
then 命令序列
fi
2
3
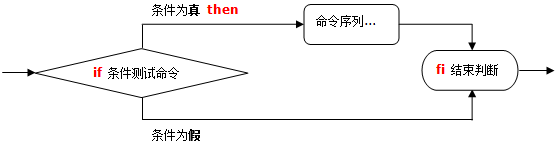 if 单分支结构流程图
if 单分支结构流程图
示例
#!/bin/bash
#当/boot分区的空间使用超过80%,就输出报警信息。
use=`df -hT | grep "/boot" | awk '{print $6}' | cut -d "%" -f1`
if [ $use -gt 80 ];
then
echo "Warning!!/boot disk is full"
fi
2
3
4
5
6
7
8
if 双分支:当“条件成立”、“条件不成立”时执行不同操作。
if 条件测试命令
then 命令序列1
else 命令序列2
fi
2
3
4
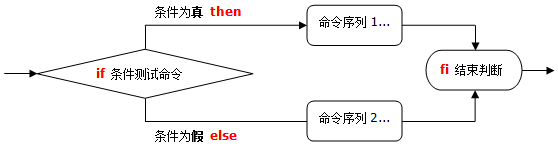 if 双分支结构流程图
if 双分支结构流程图
示例
#!/bin/bash
#判断iptables是否在运行,如果已经在运行提示信息,如果没有开启它。
service iptables status &> /dev/null
if [ $? -eq 0 ];
then
echo "iptables service is running"
else
service iptables restart
fi
2
3
4
5
6
7
8
9
if 多分支:相当于if语句嵌套,针对多个条件执行不同操作。
if 条件测试命令1 ; then
命令序列1
elif 条件测试命令2 ; then
命令序列2
elif ...
else
命令序列n
fi
2
3
4
5
6
7
8
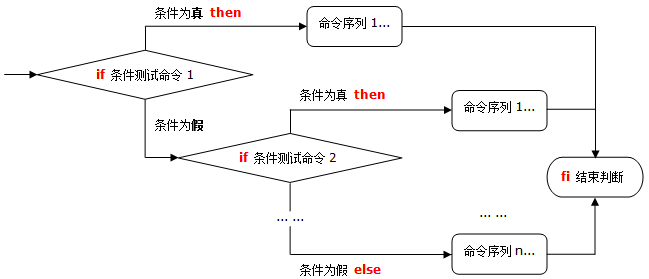 if多分支结构流程图
if多分支结构流程图
# for循环语句
根据标量的不同取值,重复执行一组命令操作。
for 变量名 in 取值列表
do
命令序列
done
2
3
4
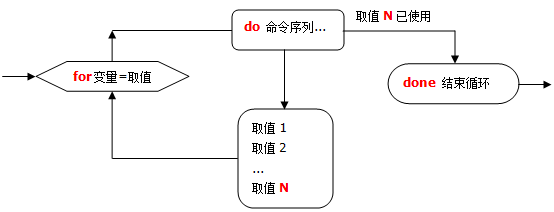 for循环语句流程图
for循环语句流程图
for循环的几种应用形式:
最基本的for循环: (传统的形式,for var in …)
#!/bin/bash
for x in one two three four
do
echo number $x
done
2
3
4
5
for循环总是接收in语句之后的某种类型的字列表。在本例中,指定了四个英语单词,但是字列表也可以引用磁盘上的文件,甚至文件通配符。
对目录中的文件做for循环
#!/bin/bash
for x in /var/log/*
do
#echo "$x is a file living in /var/log"
echo $(basename $x) is a file living in /var/log
done
2
3
4
5
6
这个$x获得的是绝对路径文件名,可以使用basename可执行程序来除去前面的路径信息。如果只引用当前工作目录中的文件(例如如果输入for x in *),则产生的文件列表将没有路径信息的前缀。
对位置参数做for循环
#!/bin/bash
for thing in "$@"
do
echo you typed ${thing}.
done
2
3
4
5
for循环中用seq产生循环次数,加上C语言形式的for循环语句
#!/bin/bash
echo "for: Traditional form: for var in ..."
for j in $(seq 1 5)
do
echo $j
done
echo "for: C language form: for (( exp1; exp2; exp3 ))"
for (( i=1; i<=5; i++ ))
do
echo "i=$i"
done
2
3
4
5
6
7
8
9
10
11
对于固定次数的循环,可以通过seq命令来实现,就不需要变量的自增了,这里的C语言for循环风格是挺熟悉的吧。
# while循环语句
重复测试指令的条件,只要条件为真则反复执行对应的命令操作,直到条件为假。如果使用true作为循环条件能够产生无限循环。
while 命令表达式
do
命令列表
done
2
3
4
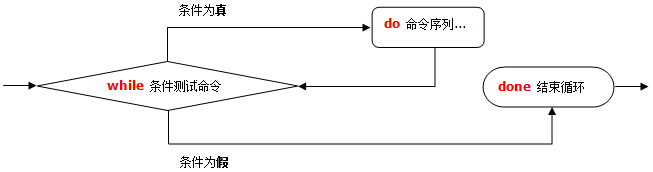 while循环流程图
while循环流程图
示例
#!/bin/bash
#批量添加20个系统账户用户名依次为user1~20
i=1
while [ $i -le 20 ]
do
useradd user$1
echo "123456" | passwd --stdin user$i &> /dev/null
i=`expr $i + 1`
done
2
3
4
5
6
7
8
9
只要特定条件为真,”while” 语句就会循环执行。
# case多重分支语句
根据变量的不通取值,分别执行不同的命令操作。
case 变量值 in
模式1)
命令序列1
;;
模式2)
命令序列2
;;
……
*)
默认执行的命令序列
;;
esac
2
3
4
5
6
7
8
9
10
11
12
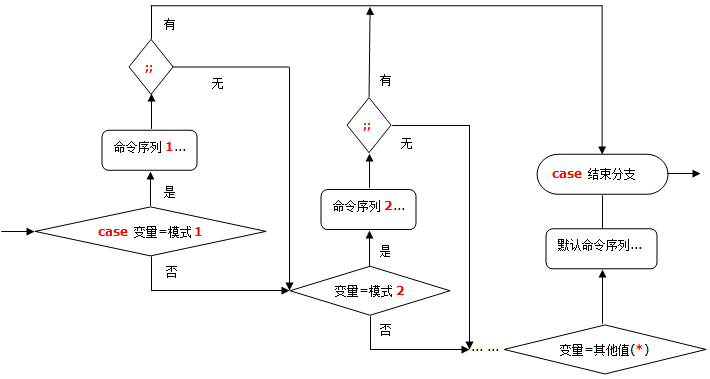 case多重分支语句流程图
case多重分支语句流程图
示例
#!/bin/bash
case $1 in
start)
echo "start mysql"
;;
stop)
echo "stop mysql"
;;
*)
echo "usage: $0 start|stop"
;;
esac
2
3
4
5
6
7
8
9
10
11
12
# until循环语句
根据条件执行重复操作,直到条件成立为止。Until语句提供了与while语句相反的功能:只要特定条件为假,它们就重复循环,直到条件为真。
until 条件测试命令
do
命令序列
done
2
3
4
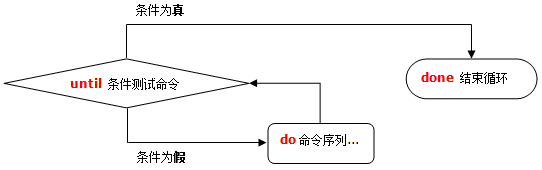 until循环流程图
until循环流程图
示例
#!/bin/bash
myvar=1
until [ $myvar -gt 10 ]
do
echo $myvar
myvar=$(( $myvar + 1 ))
done
2
3
4
5
6
7
# shift迁移语句
用于迁移位置变量,将$1~$9依次向左传递。
例如:若当前脚本程序获得的位置变量如下:
$1=file1、$2=file2、$3=file3、$4=file4
执行一次shift命令后,各位置变量为:
$2=file2、$3=file3、$4=file4
在执行一次:
$3=file3、$4=file4
示例
#!/bin/bash
res=0
while [ $# -gt 0 ]
do
res=`expr $res + $1`
shift
done
echo "the sum is:$res"
2
3
4
5
6
7
8
# 循环控制语句
break语句:在for、while、until等循环语句中,用于跳出当前所在的循环体,执行循环体之后的语句。
在while中的示例:
while
do
commands
commands
break--------+
|
commands |
commands | 跳出当前循环(通常在循环体中与条件语句一起使用)
|
done |
|
commands<-----+
commands
2
3
4
5
6
7
8
9
10
11
12
13
14
continue语句:在for、while、until等循环语句中,用于跳过循环体内余下的语句,重新判断条件以便执行下一次循环。
在while中的示例:
while<-------+
do |
|
commands | 跳回当前循环,重新开始下一次循环(通常在循环体中与条件语句一起使用)
commands |
|
continue----+
commands
commands
commands
done
commands
commands
2
3
4
5
6
7
8
9
10
11
12
13
14
# 内部字段分隔符IFS、脚本调试DEBUG
# 内部字段分隔符
**内部字段分隔符(Internal Field Separator, IFS)**是shell脚本中的一个特殊变量,在处理文本数据很有用。把单个数据流划分成不同的数据元素的定界符,内部字段分隔符就是用于特定用途的定界符。IFS是存储定界符的环境变量,是shell环境中的默认定界符字符串,默认值为空白字符(换行符、制表符、空格)
迭代一个字符串或者CSV (opens new window)(Comma Separated Value, 逗号分隔型数值)中的单词:
#!/bin/bash
data="111,222,333,444,555,666"
oldIFS=$IFS #定义一个变量为默认IFS
IFS=, #设置IFS为逗号
for i in $data
do
echo S:$i
done
IFS=$oldIFS #还原IFS为默认值
2
3
4
5
6
7
8
9
10
11
12
13
执行结果:
[root@mail text]# ./6.sh
S:111
S:222
S:333
S:444
S:555
S:666
2
3
4
5
6
7
IFS被设置为逗号(,),shell将逗号解释为一个定界符,因此变量$i在每次迭代中读取由逗号分隔的字符串作为变量值。
# Shell脚本的调试
调式功能是每种编程语言都具备的特性之一,出现一些始料未及的情况,使用调式功能可以弄清楚是什么原因发生了错误或者异常。shell脚本自身已经包含了调式选项,能都打印出脚本接受的参数和输入。
1、使用选项 -x
bash -x script.sh
或者
sh -x script.sh
2
3
4
5
-x 选项是打印所有行的信息。
2、使用 set (opens new window) +/-x ;set +/-v
- set -x:在执行时候显示参数和命令。
- set +x:禁止调式。
- set -v:当命令进入读取时候显示输入。
- set +v:禁止打印输入。
示例
#!/bin/bash
for i in {1..5}
do
set -x
echo $i
set +x
done
echo "end"
2
3
4
5
6
7
8
9
10
上例中,仅在 -x 和 +x 的区域中才会显示调式信息。
3、使用 _DEBUG 环境变量
如果需要自定义格式显示调式信息可以通过_DEBUG环境变量来建立:
#!/bin/bash
DEBUG() {
[ "$_DEBUG" = "on" ] && $@ || :
}
for i in {1..5}
do
DEBUG echo $i
done
2
3
4
5
6
7
8
9
10
将调试功能设置为“on”来运行脚本:
_DEBUG=on ./script.sh
将需要调式的行前加上DEBUG,运行脚本前没有加_DEBUG=on就不会显示任何信息,脚本中“:”告诉shell不要进行任何操作。
4、使用shebang调式方法
这是最便捷的方法。把shebang 从#!/bin/bash 修改成 #!/bin/bash -xv ,其他就不用做任何操作了。
# 切分文件名提取文件扩展名或提取文件名
有些脚本要根据文件名进行各种处理,有时候需要保留文件名抛弃文件后缀,也有时候需要文件后缀不要文件名,这类提取文件部分的操作使用shell的内建功能就能实现。需要用到的几个操作符有:%、%%、#、##。
从右向左匹配 :% 和 %% 操作符的示例
#!/bin/bash
#提取文件名,删除后缀。
file_name="text.gif"
name=${file_name%.*}
echo file name is: $name
输出结果:
file name is: test
# ${VAR%.* }含义:从$VAR中删除位于 % 右侧的通配符左右匹配的字符串,通配符从右向左进行匹配。现在给变量 name 赋值,name=text.gif,那么通配符从右向左就会匹配到 .gif,所有从 $VAR 中删除匹配结果。
# % 属于非贪婪操作符,他是从左右向左匹配最短结果;%% 属于贪婪操作符,会从右向左匹配符合条件的最长字符串。
file_name="text.gif.bak.2012"
name=${file_name%.*}
name2=${file_name%%.*}
echo file name is: $name
echo file name is: $name2
输出结果:
file name is: test.gif.bak //使用 %
file name is: test //使用 %%
操作符 %% 使用 .* 从右向左贪婪匹配到 .gif.bak.2012
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
从左向右匹配:# 和 ## 操作符示例
#!/bin/bash
#提取后缀,删除文件名。
file_name="text.gif"
suffix=${file_name#*.}
echo suffix is: $suffix
输出结果:
suffix is: gif
# ${VAR#*.} 含义:从 $VAR 中删除位于 # 右侧的通配符所匹配的字符串,通配符是左向右进行匹配。
# 跟 % 一样,# 也有贪婪操作符 ## 。
file_name="text.gif.bak.2012.txt"
suffix=${file_name#*.}
suffix2=${file_name##*.}
echo suffix is: $suffix
echo suffix is: $suffix2
输出结果:
suffix is: text.gif.bak.2012 //使用 #
suffix2 is: txt //使用 ##
操作符 ## 使用 *. 从左向右贪婪匹配到 text.gif.bak.2012
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
示例2,定义变量 url="man (opens new window).linuxde.net"
echo ${url%.*} #移除 .* 所匹配的最右边的内容。
man.linuxde
echo ${url%%.*} #将从右边开始一直匹配到最左边的 *. 移除,贪婪操作符。
man
echo ${url#*.} #移除 *. 所有匹配的最左边的内容。
linuxde.net
echo ${url##*.} #将从左边开始一直匹配到最右边的 *. 移除,贪婪操作符。
net
2
3
4
5
6
7
8
# find命令
find命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
# 语法
find(选项)(参数)
# 选项
-amin<分钟>:查找在指定时间曾被存取过的文件或目录,单位以分钟计算;
-anewer<参考文件或目录>:查找其存取时间较指定文件或目录的存取时间更接近现在的文件或目录;
-atime<24小时数>:查找在指定时间曾被存取过的文件或目录,单位以24小时计算;
-cmin<分钟>:查找在指定时间之时被更改过的文件或目录;
-cnewer<参考文件或目录>查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录;
-ctime<24小时数>:查找在指定时间之时被更改的文件或目录,单位以24小时计算;
-daystart:从本日开始计算时间;
-depth:从指定目录下最深层的子目录开始查找;
-empty:寻找文件大小为0 Byte的文件,或目录下没有任何子目录或文件的空目录;
-exec<执行指令>:假设find指令的回传值为True,就执行该指令;
-false:将find指令的回传值皆设为False;
-fls<列表文件>:此参数的效果和指定“-ls”参数类似,但会把结果保存为指定的列表文件;
-follow:排除符号连接;
-fprint<列表文件>:此参数的效果和指定“-print”参数类似,但会把结果保存成指定的列表文件;
-fprint0<列表文件>:此参数的效果和指定“-print0”参数类似,但会把结果保存成指定的列表文件;
-fprintf<列表文件><输出格式>:此参数的效果和指定“-printf”参数类似,但会把结果保存成指定的列表文件;
-fstype<文件系统类型>:只寻找该文件系统类型下的文件或目录;
-gid<群组识别码>:查找符合指定之群组识别码的文件或目录;
-group<群组名称>:查找符合指定之群组名称的文件或目录;
-help或——help:在线帮助;
-ilname<范本样式>:此参数的效果和指定“-lname”参数类似,但忽略字符大小写的差别;
-iname<范本样式>:此参数的效果和指定“-name”参数类似,但忽略字符大小写的差别;
-inum<inode编号>:查找符合指定的inode编号的文件或目录;
-ipath<范本样式>:此参数的效果和指定“-path”参数类似,但忽略字符大小写的差别;
-iregex<范本样式>:此参数的效果和指定“-regexe”参数类似,但忽略字符大小写的差别;
-links<连接数目>:查找符合指定的硬连接数目的文件或目录;
-iname<范本样式>:指定字符串作为寻找符号连接的范本样式;
-ls:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出;
-maxdepth<目录层级>:设置最大目录层级;
-mindepth<目录层级>:设置最小目录层级;
-mmin<分钟>:查找在指定时间曾被更改过的文件或目录,单位以分钟计算;
-mount:此参数的效果和指定“-xdev”相同;
-mtime<24小时数>:查找在指定时间曾被更改过的文件或目录,单位以24小时计算;
-name<范本样式>:指定字符串作为寻找文件或目录的范本样式;
-newer<参考文件或目录>:查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录;
-nogroup:找出不属于本地主机群组识别码的文件或目录;
-noleaf:不去考虑目录至少需拥有两个硬连接存在;
-nouser:找出不属于本地主机用户识别码的文件或目录;
-ok<执行指令>:此参数的效果和指定“-exec”类似,但在执行指令之前会先询问用户,若回答“y”或“Y”,则放弃执行命令;
-path<范本样式>:指定字符串作为寻找目录的范本样式;
-perm<权限数值>:查找符合指定的权限数值的文件或目录;
-print:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式为每列一个名称,每个名称前皆有“./”字符串;
-print0:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式为全部的名称皆在同一行;
-printf<输出格式>:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式可以自行指定;
-prune:不寻找字符串作为寻找文件或目录的范本样式;
-regex<范本样式>:指定字符串作为寻找文件或目录的范本样式;
-size<文件大小>:查找符合指定的文件大小的文件;
-true:将find指令的回传值皆设为True;
-type<文件类型>:只寻找符合指定的文件类型的文件;
-uid<用户识别码>:查找符合指定的用户识别码的文件或目录;
-used<日数>:查找文件或目录被更改之后在指定时间曾被存取过的文件或目录,单位以日计算;
-user<拥有者名称>:查找符和指定的拥有者名称的文件或目录;
-version或——version:显示版本信息;
-xdev:将范围局限在先行的文件系统中;
-xtype<文件类型>:此参数的效果和指定“-type”参数类似,差别在于它针对符号连接检查。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# 参数
起始目录:查找文件的起始目录。
# 实例
# 根据文件或者正则表达式进行匹配
列出当前目录及子目录下所有文件和文件夹
find .
在/home目录下查找以.txt结尾的文件名
find /home -name "*.txt"
同上,但忽略大小写
find /home -iname "*.txt"
当前目录及子目录下查找所有以.txt和.pdf结尾的文件
find . \( -name "*.txt" -o -name "*.pdf" \)
或
find . -name "*.txt" -o -name "*.pdf"
2
3
4
5
匹配文件路径或者文件
find /usr/ -path "*local*"
基于正则表达式匹配文件路径
find . -regex ".*\(\.txt\|\.pdf\)$"
同上,但忽略大小写
find . -iregex ".*\(\.txt\|\.pdf\)$"
# 否定参数
找出/home下不是以.txt结尾的文件
find /home ! -name "*.txt"
# 根据文件类型进行搜索
find . -type 类型参数
类型参数列表:
- f 普通文件
- l 符号连接
- d 目录
- c 字符设备
- b 块设备
- s 套接字
- p Fifo
# 基于目录深度搜索
向下最大深度限制为3
find . -maxdepth 3 -type f
搜索出深度距离当前目录至少2个子目录的所有文件
find . -mindepth 2 -type f
# 根据文件时间戳进行搜索
find . -type f 时间戳
UNIX/Linux文件系统每个文件都有三种时间戳:
- 访问时间(-atime/天,-amin/分钟):用户最近一次访问时间。
- 修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间。
- 变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
搜索最近七天内被访问过的所有文件
find . -type f -atime -7
搜索恰好在七天前被访问过的所有文件
find . -type f -atime 7
搜索超过七天内被访问过的所有文件
find . -type f -atime +7
搜索访问时间超过10分钟的所有文件
find . -type f -amin +10
找出比file (opens new window).log修改时间更长的所有文件
find . -type f -newer file.log
# 根据文件大小进行匹配
find . -type f -size 文件大小单元
文件大小单元:
- b —— 块(512字节)
- c —— 字节
- w (opens new window) —— 字(2字节)
- k —— 千字节
- M —— 兆字节
- G —— 吉字节
搜索大于10KB的文件
find . -type f -size +10k
搜索小于10KB的文件
find . -type f -size -10k
搜索等于10KB的文件
find . -type f -size 10k
# 删除匹配文件
删除当前目录下所有.txt文件
find . -type f -name "*.txt" -delete
# 根据文件权限/所有权进行匹配
当前目录下搜索出权限为777的文件
find . -type f -perm 777
找出当前目录下权限不是644的php (opens new window)文件
find . -type f -name "*.php" ! -perm 644
找出当前目录用户tom拥有的所有文件
find . -type f -user tom
找出当前目录用户组sunk拥有的所有文件
find . -type f -group sunk
# 借助-exec选项与其他命令结合使用
找出当前目录下所有root的文件,并把所有权更改为用户tom
find .-type f -user root -exec chown tom {} \;
上例中,{} 用于与**-exec**选项结合使用来匹配所有文件,然后会被替换为相应的文件名。
找出自己家目录下所有的.txt文件并删除
find $HOME/. -name "*.txt" -ok rm {} \;
上例中,-ok和**-exec**行为一样,不过它会给出提示,是否执行相应的操作。
查找当前目录下所有.txt文件并把他们拼接起来写入到all.txt文件中
find . -type f -name "*.txt" -exec cat {} \;> all.txt
将30天前的.log文件移动到old目录中
find . -type f -mtime +30 -name "*.log" -exec cp {} old \;
找出当前目录下所有.txt文件并以“File:文件名”的形式打印出来
find . -type f -name "*.txt" -exec printf "File: %s\n" {} \;
因为单行命令中-exec参数中无法使用多个命令,以下方法可以实现在-exec之后接受多条命令
-exec ./text.sh {} \;
# 搜索但跳出指定的目录
查找当前目录或者子目录下所有.txt文件,但是跳过子目录sk
find . -path "./sk" -prune -o -name "*.txt" -print
# find其他技巧收集
要列出所有长度为零的文件
find . -empty
find -print0表示在find的每一个结果之后加一个NULL字符,而不是默认加一个换行符。find的默认在每一个结果后加一个'\n',所以输出结果是一行一行的。当使用了-print0之后,就变成一行了
然后xargs -0表示xargs用NULL来作为分隔符。这样前后搭配就不会出现空格和换行符的错误了。选择NULL做分隔符,是因为一般编程语言把NULL作为字符串结束的标志,所以文件名不可能以NULL结尾,这样确保万无一失。
find . -name "*.txt" -print0 | xargs -0 rm
查找类型文件并修改内容
find ./ -type f -regex ".*.tpl" | xargs sed -i "s#MinDoc文档在线管理系统#小诺运维、运维笔记#g"
find ./ -type f -regex ".*.tpl" | xargs grep "meta name="description" content="
# xargs命令
xargs命令是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具。它擅长将标准输入数据转换成命令行参数,xargs能够处理管道或者stdin并将其转换成特定命令的命令参数。xargs也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。xargs的默认命令是echo (opens new window),空格是默认定界符。这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。xargs是构建单行命令的重要组件之一。
# xargs命令用法
xargs用作替换工具,读取输入数据重新格式化后输出。
定义一个测试文件,内有多行文本数据:
cat test.txt
a b c d e f g
h i j k l m n
o p q
r s t
u v w x y z
2
3
4
5
6
7
多行输入单行输出:
cat test.txt | xargs
a b c d e f g h i j k l m n o p q r s t u v w x y z
2
3
-n选项多行输出:
cat test.txt | xargs -n3
a b c
d e f
g h i
j k l
m n o
p q r
s t u
v w x
y z
2
3
4
5
6
7
8
9
10
11
-d选项可以自定义一个定界符:
echo "nameXnameXnameXname" | xargs -dX
name name name name
2
3
结合**-n选项**使用:
echo "nameXnameXnameXname" | xargs -dX -n2
name name
name name
2
3
4
读取stdin,将格式化后的参数传递给命令
假设一个命令为 sk.sh 和一个保存参数的文件arg.txt:
#!/bin/bash
#sk.sh命令内容,打印出所有参数。
echo $*
2
3
4
arg.txt文件内容:
cat arg.txt
aaa
bbb
ccc
2
3
4
5
xargs的一个选项-I,使用-I指定一个替换字符串{},这个字符串在xargs扩展时会被替换掉,当-I与xargs结合使用,每一个参数命令都会被执行一次:
cat arg.txt | xargs -I {} ./sk.sh -p {} -l
-p aaa -l
-p bbb -l
-p ccc -l
2
3
4
5
复制所有图片文件到 /data/images 目录下:
ls *.jpg | xargs -n1 -I cp {} /data/images
xargs结合find (opens new window)使用
用rm (opens new window) 删除太多的文件时候,可能得到一个错误信息:/bin/rm Argument list too long. 用xargs去避免这个问题:
find . -type f -name "*.log" -print0 | xargs -0 rm -f
xargs -0将\0作为定界符。
统计一个源代码目录中所有php (opens new window)文件的行数:
find . -type f -name "*.php" -print0 | xargs -0 wc -l
查找所有的jpg 文件,并且压缩它们:
find . -type f -name "*.jpg" -print | xargs tar -czvf images.tar.gz
xargs其他应用
假如你有一个文件包含了很多你希望下载的URL,你能够使用xargs下载所有链接:
cat url-list.txt | xargs wget -c
# 子Shell(Subshells)
运行一个shell脚本时会启动另一个命令解释器.,就好像你的命令是在命令行提示下被解释的一样,类似于批处理文件里的一系列命令。每个shell脚本有效地运行在父shell(parent shell)的一个子进程里。这个父shell是指在一个控制终端或在一个xterm窗口中给你命令指示符的进程。
cmd1 | ( cmd2; cmd3; cmd4 ) | cmd5
如果cmd2 是cd (opens new window) /,那么就会改变子Shell的工作目录,这种改变只是局限于子shell内部,cmd5则完全不知道工作目录发生的变化。子shell是嵌在圆括号()内部的命令序列,子Shell内部定义的变量为局部变量。
子shell可用于为一组命令设定临时的环境变量:
COMMAND1
COMMAND2
COMMAND3
(
IFS=:
PATH=/bin
unset TERMINFO
set -C
shift 5
COMMAND4
COMMAND5
exit 3 # 只是从子shell退出。
)
# 父shell不受影响,变量值没有更改。
COMMAND6
COMMAND7
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# tar命令
tar命令可以为linux的文件和目录创建档案。利用tar,可以为某一特定文件创建档案(备份文件),也可以在档案中改变文件,或者向档案中加入新的文件。tar最初被用来在磁带上创建档案,现在,用户可以在任何设备上创建档案。利用tar命令,可以把一大堆的文件和目录全部打包成一个文件,这对于备份文件或将几个文件组合成为一个文件以便于网络传输是非常有用的。
首先要弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件。
为什么要区分这两个概念呢?这源于Linux中很多压缩程序只能针对一个文件进行压缩,这样当你想要压缩一大堆文件时,你得先将这一大堆文件先打成一个包(tar命令),然后再用压缩程序进行压缩(gzip (opens new window) bzip2 (opens new window)命令)。
# 语法
tar(选项)(参数)
# 选项
-A或--catenate:新增文件到以存在的备份文件;
-B:设置区块大小;
-c或--create:建立新的备份文件;
-C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
-d:记录文件的差别;
-x或--extract或--get:从备份文件中还原文件;
-t或--list:列出备份文件的内容;
-z或--gzip或--ungzip:通过gzip指令处理备份文件;
-Z或--compress或--uncompress:通过compress指令处理备份文件;
-f<备份文件>或--file=<备份文件>:指定备份文件;
-v或--verbose:显示指令执行过程;
-r:添加文件到已经压缩的文件;
-u:添加改变了和现有的文件到已经存在的压缩文件;
-j:支持bzip2解压文件;
-v:显示操作过程;
-l:文件系统边界设置;
-k:保留原有文件不覆盖;
-m:保留文件不被覆盖;
-w:确认压缩文件的正确性;
-p或--same-permissions:用原来的文件权限还原文件;
-P或--absolute-names:文件名使用绝对名称,不移除文件名称前的“/”号;
-N <日期格式> 或 --newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里;
--exclude=<范本样式>:排除符合范本样式的文件。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 参数
文件或目录:指定要打包的文件或目录列表。
# 实例
将文件全部打包成tar包:
tar -cvf log.tar log2012.log 仅打包,不压缩!
tar -zcvf log.tar.gz log2012.log 打包后,以 gzip 压缩
tar -jcvf log.tar.bz2 log2012.log 打包后,以 bzip2 压缩
2
3
在选项f之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。 如果加z选项,则以.tar.gz或.tgz来代表gzip压缩过的tar包;如果加j选项,则以.tar.bz2来作为tar包名。
查阅上述tar包内有哪些文件:
tar -ztvf log.tar.gz
由于我们使用 gzip 压缩的log.tar.gz,所以要查阅log.tar.gz包内的文件时,就得要加上z这个选项了。
将tar包解压缩:
tar -zxvf /opt/soft/test/log.tar.gz
在预设的情况下,我们可以将压缩档在任何地方解开的
只将tar内的部分文件解压出来:
tar -zxvf /opt/soft/test/log30.tar.gz log2013.log
我可以透过tar -ztvf来查阅 tar 包内的文件名称,如果单只要一个文件,就可以透过这个方式来解压部分文件!
文件备份下来,并且保存其权限:
tar -zcvpf log31.tar.gz log2014.log log2015.log log2016.log
这个-p的属性是很重要的,尤其是当您要保留原本文件的属性时。
在文件夹当中,比某个日期新的文件才备份:
tar -N "2012/11/13" -zcvf log17.tar.gz test
备份文件夹内容是排除部分文件:
tar --exclude scf/service -zcvf scf.tar.gz scf/*
其实最简单的使用 tar 就只要记忆底下的方式即可:
压 缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
查 询:tar -jtv -f filename.tar.bz2
解压缩:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
2
3
# date命令
date命令是显示或设置系统时间与日期。
很多shell脚本里面需要打印不同格式的时间或日期,以及要根据时间和日期执行操作。延时通常用于脚本执行过程中提供一段等待的时间。日期可以以多种格式去打印,也可以使用命令设置固定的格式。在类UNIX系统中,日期被存储为一个整数,其大小为自世界标准时间(UTC)1970年1月1日0时0分0秒起流逝的秒数。
# 语法
date(选项)(参数)
# 选项
-d<字符串>:显示字符串所指的日期与时间。字符串前后必须加上双引号;
-s<字符串>:根据字符串来设置日期与时间。字符串前后必须加上双引号;
-u:显示GMT;
--help:在线帮助;
--version:显示版本信息。
2
3
4
5
# 参数
<+时间日期格式>:指定显示时使用的日期时间格式。
# 日期格式字符串列表
%H 小时,24小时制(00~23)
%I 小时,12小时制(01~12)
%k 小时,24小时制(0~23)
%l 小时,12小时制(1~12)
%M 分钟(00~59)
%p 显示出AM或PM
%r 显示时间,12小时制(hh:mm:ss %p)
%s 从1970年1月1日00:00:00到目前经历的秒数
%S 显示秒(00~59)
%T 显示时间,24小时制(hh:mm:ss)
%X 显示时间的格式(%H:%M:%S)
%Z 显示时区,日期域(CST)
%a 星期的简称(Sun~Sat)
%A 星期的全称(Sunday~Saturday)
%h,%b 月的简称(Jan~Dec)
%B 月的全称(January~December)
%c 日期和时间(Tue Nov 20 14:12:58 2012)
%d 一个月的第几天(01~31)
%x,%D 日期(mm/dd/yy)
%j 一年的第几天(001~366)
%m 月份(01~12)
%w 一个星期的第几天(0代表星期天)
%W 一年的第几个星期(00~53,星期一为第一天)
%y 年的最后两个数字(1999则是99)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 实例
格式化输出:
date +"%Y-%m-%d"
2009-12-07
2
输出昨天日期:
date -d "1 day ago" +"%Y-%m-%d"
2012-11-19
2
2秒后输出:
date -d "2 second" +"%Y-%m-%d %H:%M.%S"
2012-11-20 14:21.31
2
传说中的 1234567890 秒:
date -d "1970-01-01 1234567890 seconds" +"%Y-%m-%d %H:%m:%S"
2009-02-13 23:02:30
2
普通转格式:
date -d "2009-12-12" +"%Y/%m/%d %H:%M.%S"
2009/12/12 00:00.00
2
apache格式转换:
date -d "Dec 5, 2009 12:00:37 AM" +"%Y-%m-%d %H:%M.%S"
2009-12-05 00:00.37
2
格式转换后时间游走:
date -d "Dec 5, 2009 12:00:37 AM 2 year ago" +"%Y-%m-%d %H:%M.%S"
2007-12-05 00:00.37
2
加减操作:
date +%Y%m%d //显示前天年月日
date -d "+1 day" +%Y%m%d //显示前一天的日期
date -d "-1 day" +%Y%m%d //显示后一天的日期
date -d "-1 month" +%Y%m%d //显示上一月的日期
date -d "+1 month" +%Y%m%d //显示下一月的日期
date -d "-1 year" +%Y%m%d //显示前一年的日期
date -d "+1 year" +%Y%m%d //显示下一年的日期
2
3
4
5
6
7
设定时间:
date -s //设置当前时间,只有root权限才能设置,其他只能查看
date -s 20120523 //设置成20120523,这样会把具体时间设置成空00:00:00
date -s 01:01:01 //设置具体时间,不会对日期做更改
date -s "01:01:01 2012-05-23" //这样可以设置全部时间
date -s "01:01:01 20120523" //这样可以设置全部时间
date -s "2012-05-23 01:01:01" //这样可以设置全部时间
date -s "20120523 01:01:01" //这样可以设置全部时间
2
3
4
5
6
7
有时需要检查一组命令花费的时间,举例:
#!/bin/bash
start=$(date +%s)
nmap man.linuxde.net &> /dev/null
end=$(date +%s)
difference=$(( end - start ))
echo $difference seconds.
2
3
4
5
6
7
8
# dd命令
dd命令用于复制文件并对原文件的内容进行转换和格式化处理。dd命令功能很强大的,对于一些比较底层的问题,使用dd命令往往可以得到出人意料的效果。用的比较多的还是用dd来备份裸设备。但是不推荐,如果需要备份oracle裸设备,可以使用rman备份,或使用第三方软件备份,使用dd的话,管理起来不太方便。
建议在有需要的时候使用dd 对物理磁盘操作,如果是文件系统的话还是使用tar (opens new window) backup cpio (opens new window)等其他命令更加方便。另外,使用dd对磁盘操作时,最好使用块设备文件。
# 语法
dd(选项)
# 选项
bs=<字节数>:将 ibs(输入)与 obs(输出)设成指定的字节数;
cbs=<字节数>:转换时,每次只转换指定的字节数;
conv=<关键字>:指定文件转换的方式;
count=<区块数>:仅读取指定的区块数;
ibs=<字节数>:每次读取的字节数;
obs=<字节数>:每次输出的字节数;
of=<文件>:输出到文件;
seek=<区块数>:一开始输出时,跳过指定的区块数;
skip=<区块数>:一开始读取时,跳过指定的区块数;
--help:帮助;
--version:显示版本信息。
2
3
4
5
6
7
8
9
10
11
# 实例
[root@localhost text]# dd if=/dev/zero of=sun.txt bs=1M count=1
1+0 records in
1+0 records out
1048576 bytes (1.0 MB) copied, 0.006107 seconds, 172 MB/s
[root@localhost text]# du -sh sun.txt
1.1M sun.txt
2
3
4
5
6
7
该命令创建了一个1M大小的文件sun.txt,其中参数解释:
- if 代表输入文件。如果不指定if,默认就会从stdin中读取输入。
- of 代表输出文件。如果不指定of,默认就会将stdout作为默认输出。
- bs 代表字节为单位的块大小。
- count 代表被复制的块数。
- /dev/zero 是一个字符设备,会不断返回0值字节(\0)。
块大小可以使用的计量单位表
| 单元大小 | 代码 |
|---|---|
| 字节(1B) | c |
| 字节(2B) | w (opens new window) |
| 块(512B) | b |
| 千字节(1024B) | k |
| 兆字节(1024KB) | M |
| 吉字节(1024MB) | G |
以上命令可以看出dd命令来测试内存操作速度:
1048576 bytes (1.0 MB) copied, 0.006107 seconds, 172 MB/s
# curl命令
curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、ftp (opens new window)等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。
# 语法
curl(选项)(参数)
# 选项
| -a/--append | 上传文件时,附加到目标文件 |
|---|---|
| -A/--user-agent | 设置用户代理发送给服务器 |
| -anyauth | 可以使用“任何”身份验证方法 |
| -b/--cookie <name=string/file (opens new window)> | cookie字符串或文件读取位置 |
| --basic | 使用HTTP基本验证 |
| -B/--use-ascii | 使用ASCII /文本传输 |
| -c/--cookie-jar | 操作结束后把cookie写入到这个文件中 |
| -C/--continue-at (opens new window) | 断点续转 |
| -d/--data | HTTP POST方式传送数据 |
| --data-ascii | 以ascii的方式post数据 |
| --data-binary | 以二进制的方式post数据 |
| --negotiate | 使用HTTP身份验证 |
| --digest | 使用数字身份验证 |
| --disable-eprt | 禁止使用EPRT或LPRT |
| --disable-epsv | 禁止使用EPSV |
| -D/--dump (opens new window)-header | 把header信息写入到该文件中 |
| --egd-file | 为随机数据(SSL)设置EGD socket路径 |
| --tcp-nodelay | 使用TCP_NODELAY选项 |
| -e/--referer | 来源网址 |
| -E/--cert <cert[:passwd (opens new window)]> | 客户端证书文件和密码 (SSL) |
| --cert-type (opens new window) | 证书文件类型 (DER/PEM/ENG) (SSL) |
| --key | 私钥文件名 (SSL) |
| --key-type | 私钥文件类型 (DER/PEM/ENG) (SSL) |
| --pass | 私钥密码 (SSL) |
| --engine | 加密引擎使用 (SSL). "--engine list" for list |
| --cacert | CA证书 (SSL) |
| --capath | CA目录 (made using c_rehash) to verify peer against (SSL) |
| --ciphers | SSL密码 |
| --compressed | 要求返回是压缩的形势 (using deflate or gzip (opens new window)) |
| --connect-timeout | 设置最大请求时间 |
| --create-dirs (opens new window) | 建立本地目录的目录层次结构 |
| --crlf | 上传是把LF转变成CRLF |
| -f/--fail | 连接失败时不显示http错误 |
| --ftp-create-dirs | 如果远程目录不存在,创建远程目录 |
| --ftp-method [multicwd/nocwd/singlecwd] | 控制CWD的使用 |
| --ftp-pasv | 使用 PASV/EPSV 代替端口 |
| --ftp-skip-pasv-ip (opens new window) | 使用PASV的时候,忽略该IP地址 |
| --ftp-ssl | 尝试用 SSL/TLS 来进行ftp数据传输 |
| --ftp-ssl-reqd | 要求用 SSL/TLS 来进行ftp数据传输 |
| -F/--form <name=content> | 模拟http表单提交数据 |
| --form-string <name=string> | 模拟http表单提交数据 |
| -g/--globoff | 禁用网址序列和范围使用{}和[] |
| -G/--get | 以get的方式来发送数据 |
| -H/--header | 自定义头信息传递给服务器 |
| --ignore-content-length | 忽略的HTTP头信息的长度 |
| -i/--include | 输出时包括protocol头信息 |
| -I/--head (opens new window) | 只显示请求头信息 |
| -j/--junk-session-cookies | 读取文件进忽略session cookie |
| --interface | 使用指定网络接口/地址 |
| --krb4 | 使用指定安全级别的krb4 |
| -k/--insecure | 允许不使用证书到SSL站点 |
| -K/--config | 指定的配置文件读取 |
| -l/--list-only | 列出ftp目录下的文件名称 |
| --limit-rate | 设置传输速度 |
| --local-port | 强制使用本地端口号 |
| -m/--max-time (opens new window) | 设置最大传输时间 |
| --max-redirs | 设置最大读取的目录数 |
| --max-filesize | 设置最大下载的文件总量 |
| -M/--manual | 显示全手动 |
| -n/--netrc | 从netrc文件中读取用户名和密码 |
| --netrc-optional | 使用 .netrc 或者 URL来覆盖-n |
| --ntlm | 使用 HTTP NTLM 身份验证 |
| -N/--no-buffer | 禁用缓冲输出 |
| -o/--output | 把输出写到该文件中 |
| -O/--remote-name | 把输出写到该文件中,保留远程文件的文件名 |
| -p/--proxytunnel | 使用HTTP代理 |
| --proxy-anyauth | 选择任一代理身份验证方法 |
| --proxy-basic | 在代理上使用基本身份验证 |
| --proxy-digest | 在代理上使用数字身份验证 |
| --proxy-ntlm | 在代理上使用ntlm身份验证 |
| -P/--ftp-port | 使用端口地址,而不是使用PASV |
| -q | 作为第一个参数,关闭 .curlrc |
| -Q/--quote | 文件传输前,发送命令到服务器 |
| -r/--range | 检索来自HTTP/1.1或FTP服务器字节范围 |
| --range-file | 读取(SSL)的随机文件 |
| -R/--remote-time | 在本地生成文件时,保留远程文件时间 |
| --retry | 传输出现问题时,重试的次数 |
| --retry-delay | 传输出现问题时,设置重试间隔时间 |
| --retry-max-time | 传输出现问题时,设置最大重试时间 |
| -s/--silent | 静默模式。不输出任何东西 |
| -S/--show-error | 显示错误 |
| --socks4 <host (opens new window)[:port]> | 用socks4代理给定主机和端口 |
| --socks5 <host[:port]> | 用socks5代理给定主机和端口 |
| --stderr | |
| -t/--telnet (opens new window)-option <OPT=val> | Telnet选项设置 |
| --trace | 对指定文件进行debug |
| --trace-ascii | Like --跟踪但没有hex输出 |
| --trace-time | 跟踪/详细输出时,添加时间戳 |
| -T/--upload-file | 上传文件 |
| --url | Spet URL to work with |
| -u/--user <user[:password]> | 设置服务器的用户和密码 |
| -U/--proxy-user <user[:password]> | 设置代理用户名和密码 |
| -w (opens new window)/--write (opens new window)-out [format] | 什么输出完成后 |
| -x/--proxy <host[:port]> | 在给定的端口上使用HTTP代理 |
| -X/--request <command (opens new window)> | 指定什么命令 |
| -y/--speed-time | 放弃限速所要的时间,默认为30 |
| -Y/--speed-limit | 停止传输速度的限制,速度时间 |
# 实例
文件下载
curl命令可以用来执行下载、发送各种HTTP请求,指定HTTP头部等操作。如果系统没有curl可以使用yum install curl安装,也可以下载安装。curl是将下载文件输出到stdout,将进度信息输出到stderr,不显示进度信息使用--silent选项。
curl URL --silent
这条命令是将下载文件输出到终端,所有下载的数据都被写入到stdout。
使用选项-O将下载的数据写入到文件,必须使用文件的绝对地址:
curl http://man.linuxde.net/text.iso --silent -O
选项-o将下载数据写入到指定名称的文件中,并使用--progress显示进度条:
curl http://man.linuxde.net/test.iso -o filename.iso --progress
######################################### 100.0%
2
断点续传
curl能够从特定的文件偏移处继续下载,它可以通过指定一个便移量来下载部分文件:
curl URL/File -C 偏移量
#偏移量是以字节为单位的整数,如果让curl自动推断出正确的续传位置使用-C -:
curl -C -URL
2
3
4
使用curl设置参照页字符串
参照页是位于HTTP头部中的一个字符串,用来表示用户是从哪个页面到达当前页面的,如果用户点击网页A中的某个连接,那么用户就会跳转到B网页,网页B头部的参照页字符串就包含网页A的URL。
使用--referer选项指定参照页字符串:
curl --referer http://www.google.com http://man.linuxde.net
用curl设置cookies
使用--cookie "COKKIES"选项来指定cookie,多个cookie使用分号分隔:
curl http://man.linuxde.net --cookie "user=root;pass=123456"
将cookie另存为一个文件,使用--cookie-jar选项:
curl URL --cookie-jar cookie_file
用curl设置用户代理字符串
有些网站访问会提示只能使用IE浏览器来访问,这是因为这些网站设置了检查用户代理,可以使用curl把用户代理设置为IE,这样就可以访问了。使用--user-agent或者-A选项:
curl URL --user-agent "Mozilla/5.0"
curl URL -A "Mozilla/5.0"
2
其他HTTP头部信息也可以使用curl来发送,使用-H"头部信息" 传递多个头部信息,例如:
curl -H "Host:man.linuxde.net" -H "accept-language:zh-cn" URL
curl的带宽控制和下载配额
使用--limit-rate限制curl的下载速度:
curl URL --limit-rate 50k
命令中用k(千字节)和m(兆字节)指定下载速度限制。
使用--max-filesize指定可下载的最大文件大小:
curl URL --max-filesize bytes
如果文件大小超出限制,命令则返回一个非0退出码,如果命令正常则返回0。
用curl进行认证
使用curl选项 -u 可以完成HTTP或者FTP的认证,可以指定密码,也可以不指定密码在后续操作中输入密码:
curl -u user:pwd http://man.linuxde.net
curl -u user http://man.linuxde.net
2
只打印响应头部信息
通过-I或者-head可以只打印出HTTP头部信息:
[root@localhost text]# curl -I http://man.linuxde.net
HTTP/1.1 200 OK
Server: nginx/1.2.5
date: Mon, 10 Dec 2012 09:24:34 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
Vary: Accept-Encoding
X-Pingback: http://man.linuxde.net/xmlrpc.php
2
3
4
5
6
7
8
# Shell脚本中的while getopts用法
getpots是Shell命令行参数解析工具,旨在从Shell Script的命令行当中解析参数。getopts被Shell程序用来分析位置参数,option包含需要被识别的选项字符,如果这里的字符后面跟着一个冒号,表明该字符选项需要一个参数,其参数需要以空格分隔。冒号和问号不能被用作选项字符。getopts每次被调用时,它会将下一个选项字符放置到变量中,OPTARG则可以拿到参数值;如果option前面加冒号,则代表忽略错误;
命令格式:
getopts optstring name [arg...]
命令描述: optstring列出了对应的Shell Script可以识别的所有参数。比如:如果 Shell Script可以识别-a,-f以及-s参数,则optstring就是afs;如果对应的参数后面还跟随一个值,则在相应的optstring后面加冒号。比如,a:fs 表示a参数后面会有一个值出现,-a value的形式。另外,getopts执行匹配到a的时候,会把value存放在一个叫OPTARG的Shell Variable当中。如果 optstring是以冒号开头的,命令行当中出现了optstring当中没有的参数将不会提示错误信息。
name表示的是参数的名称,每次执行getopts,会从命令行当中获取下一个参数,然后存放到name当中。如果获取到的参数不在optstring当中列出,则name的值被设置为?。命令行当中的所有参数都有一个index,第一个参数从1开始,依次类推。 另外有一个名为OPTIND的Shell Variable存放下一个要处理的参数的index。
# Shell编程之Expect自动化交互程序
# Expect自动化交互程序
# 1.spawn命令
通过spawn执行一个命令或程序,之后所有的Expect操作都会在这个执行过的命令或程序进程中进行,包括自动交互功能。
语法: spawn [ 选项 ] [ 需要自动交互的命令或程序 ]
- -open 表示启动文件进程
- -ignore 表示忽略某些信号
spawn ssh root@192.168.1.1 uptime
# 2.expect命令
获取spawn命令执行后的信息,看卡是否和其事先指定的相匹配,一旦匹配上指定的内容就执行expect
语法: expect 表达式 [ 动作 ]
spawn ssh root@192.168.1.1 uptime
expect "*password" {sshd "123456\r"}
2
# 3.expect实践
(1)执行ssh命令远程获取服务器负载,并实现自动输入密码
[root@codis-178 ~]# cat 18_1.sh
#!/bin/expect
#Author:xiaoda
#Time:2017-09-06 11:53:30
#Name:18_1.sh
#Version:V1.0
#Description:This is a test script
spawn ssh -p12541 test@192.168.1.22 uptime
expect "*password" {send "123456\n"}
expect eof
[root@codis-178 ~]# expect 18_1.sh
spawn ssh -p12541 test@192.168.1.22 uptime
Address 192.168.1.22 maps to localhost, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!
test@192.168.1.22's password:
11:56:01 up 1754 days, 23:53, 0 users, load average: 0.00, 0.00, 0.00
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
说明: 通过spawn执行ssh后,系统会提示输入密码,expect按照匹配password字符串,之后根据send或exp_send动作执行。
(2)执行ssh命令远程获取服务器负载,并自动输入“yes”及用户密码
[root@codis-178 ~]# cat 18_2.sh
#!/bin/expect
#Author:xiaoda
#Time:2017-09-06 11:53:30
#Name:18_1.sh
#Version:V1.0
#Description:This is a test script
spawn ssh -p12541 test@192.168.1.22 uptime
expect {
"yes/no" {exp_send "yes\r";exp_continue}
"*password" {exp_send "12345465\r"}
}
expect eof
[root@codis-178 ~]# expect 18_2.sh
spawn ssh -p12541 test@192.168.1.22 uptime
Address 192.168.1.22 maps to localhost, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!
test@192.168.1.22's password:
12:03:18 up 1755 days, 1 min, 0 users, load average: 0.00, 0.00, 0.00
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
(3)利用expect响应Shell脚本中的多个read读入
[root@codis-178 ~]# cat 18_3_1.sh
#!/bin/bash
#Author:xiaoda
#Time:2017-09-06 12:05:38
#Name:18_3_1.sh
#Version:V1.0
#Description:This is a test script
read -p 'Please input your username:' name
read -p 'Please input your password:' pass
read -p 'Please input your email:' email
echo -n "your name is $name."
echo -n "your password is $pass."
echo "your email is $email."
[root@codis-178 ~]# cat 18_3_2.sh
#!/bin/expect
#Author:xiaoda
#Time:2017-09-06 12:07:37
#Name:18_3_2.sh
#Version:V1.0
#Description:This is a test script
spawn /bin/sh 18_3_1.sh
expect {
"username" {exp_send "oldboy\r";exp_continue}
"*pass*" {send "123456\r";exp_continue}
"*email*" {exp_send "12313@.qq.com\r"}
}
expect eof'
[root@codis-178 ~]# expect 18_3_2.sh
spawn /bin/sh 18_3_1.sh
Please input your username:oldboy
Please input your password:123456
Please input your email:12313@.qq.com
your name is oldboy.your password is 123456.your email is 12313@.qq.com.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 4.命令简介
(1)send命令 发送指定的字符串给系统
(2)exp_continue命令 让Expect程序继续匹配
(3)send_user命令 用来打印Expect脚本信息,类似echo
(4)exit命令 直接退出Expect脚本

# 5.Expect关键字
(1)eof 用于匹配结束符
(2)timeout 控制时间,是一个全局性的时间控制开关,可以通过为这个变量赋值来规定整个Expect操作的时间 (即使命令没有任何错误,到了时间仍然会激活这个变量)
spqwn ssh root@192.168.1.1 uptime
set timeout 30
expect "yes/no" {exp_send "yes\r";exp_continue}
expect timeout {puts "Request timeout by oldboy.";return}
spqwn ssh root@192.168.1.1 uptime
expect {
-timeout 3
expect "yes/no" {exp_send "yes\r";exp_continue}
expect timeout {puts "Request timeout by oldboy.";return}
}
2
3
4
5
6
7
8
9
10
# 6.企业应用
(1)实现Expect自动交互
#!/usr/bin/expect
if [ $argc != 2 ] {
puts "usage: expect $argv0 ip command"
exit
}
set ip [lindex $argv 0]
set cmd [lindex $argv 1]
set password "123456"
spawn ssh root@192.168.1.1 $cmd
expect {
expect "yes/no" {exp_send "yes\r";exp_continue}
"*password" {send "$password\r"}
}
export eof
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
(2)批量发送文件
#!/usr/bin/expect
if [ $argc != 3 ] {
puts "usage: expect $argv0 file host dir"
exit
}
set file [lindex $argv 0]
set host [lindex $argv 1]
set dir [lindex $argv 2]
set password "123456"
spawn ssh -P22 root@192.168.1.1 $cmd
expect {
expect "yes/no" {exp_send "yes\r";exp_continue}
"*password" {send "$password\r"}
}
export eof
#!/bin/bash
if [ $# -ne 2 ];then
echo $"Usage:$0 file dir"
exit 1
fi
file=$1
dir=$2
for n in 128 129 130
do
expect 18_13_1.exp $file 192.168.1.$n $dir
done
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 7.关于使用expect自动退出
interact:表示登录远程机器后保留在登录的机器。如果不加这个interact,则登录后立马退出。或者使用 expect eof 这个命令,则会在登录机器后的2-3s后退出
不支持在EOF中使用
# 8.设置变量
set host 192.168.200.200
# 脚本开发练习
1、各类监控脚本,文件、内存、磁盘、端口,URL 监控报警。 2、如何监控网站目录文件是否被篡改,以及站点目录批量被篡改后如何恢复。 3、如何开发各类服务rsync、nginx、mysql等的启动及停止专业脚本(使用chkconfig管理)。 4、如何开发MySQL主从复制监控报警以及自动处理不复制的脚本。· 5、一键配置mysql 多实例、一键配置mysql主从,N多一键部署脚本 6、监控http/mysql/rsync/nfs/memcached等服务是否异常的生产脚本。。 7、一键软件安装及优化,lanmp, linux一键优化,一键数据库安装,优化,配置主从。 8、MySQL多实例启动脚本,分库、分表自动备份脚本。 9、根据网络连接数以及根据 web日志PV封IP的脚本。 10、监控网站的pv以及流量,并且对流量信息进行统计。 11、检查web 服务器多个URL地址是否异常,要可以批量及通用。 12、系统的基础优化一键优化的脚本。 13、清理系统垃圾及文件(过期备份,clientmquene目录等)脚本。 14、tcp连接状态统计。 15、批量创建用户并设置随机8位密码。 16、批量获取服务器信息、批量分发文件。·
脚本注释规范