 web服务器性能估计
web服务器性能估计
在给客户做方案的时候,或者在软件设计的时候,或者在软件测试的时候,我们经常会估算我们的web应用程序的性能。这样,我们才能正确的设计方案。 如果估算误差太大,你给客户的方案是10台服务器,实际部署时确需要20台机器,客户绝对要疯了。同样对我们的代码设计和测试方案影响重大。 那么在带宽和内存都很充足的情况下我们如何大致估算出一个web应用程序的性能呢?
首先,我们看一张Tengine/Nginx的性能图,根据这个例子来演示一下性能的估算。此图摘自Tengine & Nginx Benchmark (opens new window)。
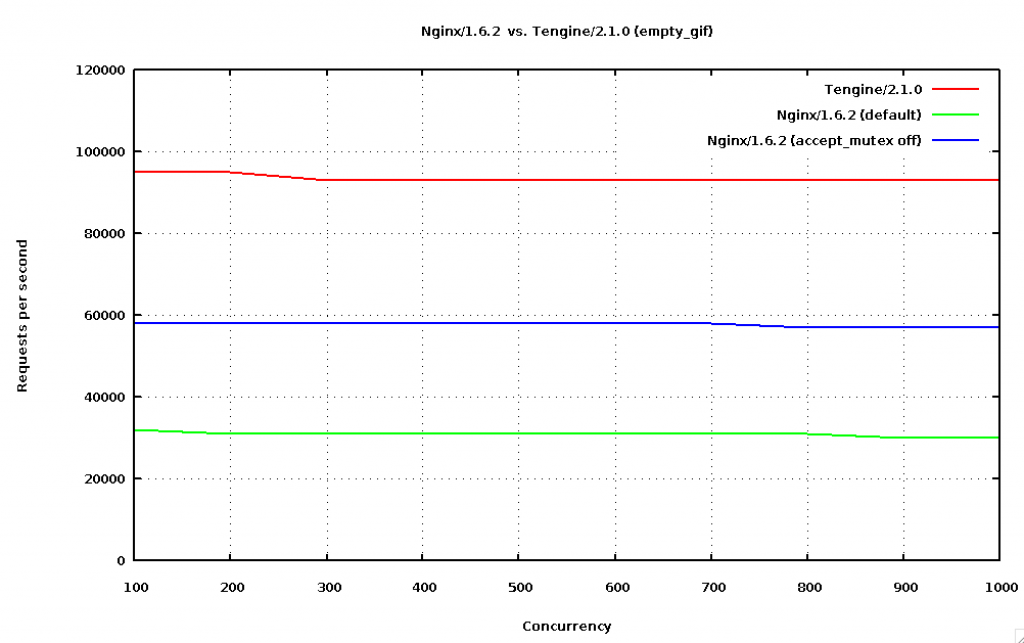
可以看到Tengine的 RPS (requests per seconds)可以达到90000多,并发数大一点的时候RPS会大一点,随后随之并发数的增大RPS并没有随之增大,而是略微减小。这也可以理解,对大部分web应用来说,连接数增多了,资源占用和维护的花费也增多了。 作为粗略的估算方法,我们忽略并发数的影响,可以大致Tengine可以达到90000请求每秒。 这个测试是利用apache ab访问一个gif文件进行测试的:
ab -r -n 10000000 -c 100 http://ip:81/empty.gif
测试环境是:
CPU: Intel(R)Xeon(R)E5-2650v2@2.60GHz 32core
Memory: 128GB
NIC: Intel Corporation 82599EB 10-Gigabit SFI/SFP+ Network Connection
Kernel: Linux-3.17.2.x86_64
Tengine-2.1.0
Nginx-1.6.2
ApacheBench-2.3
2
3
4
5
6
7
这是一台32个core的服务器,10G带宽。
基本上每个core可以达到90000/32 ≈ 2800 请求每秒。 因此我们可以估算8个core的服务器可以达到2800 * 8 ≈ 22000请求每秒。 当然这些是大致估算,实际RPS并不和core的数量成严格正比关系,但在请求之间没有影响或者影响不大(比如数据库操作)的情况下误差应该不是很大。 平均每个请求的花费的时间大约为1000 / 2800 ≈ 0.36ms。
根据上面的估算方法,我们可以得出估算的公式:
在带宽和内存不是问题的时候,全部的core都用来处理请求的情况下, 如果一个请求花费的时间是 t毫秒, 单个core的RPS可以达到
1000 /t。 n个core的RPS可以达到n * 1000 /t。在带宽和内存不是问题的时候,全部的core都用来处理请求的情况下, 如果n个core的RPS是 N, 单个core的RPS是
N /n, 一个请求的平均花费是1000 * n / N毫秒。
举个例子,如果我们的业务比较复杂,每个请求大约需要100ms才能,完成,那么单个core所能达到的RPS = 1000/100 = 10 requests/s,在32个core的服务器 上也只能达到32 * 10 =320 requests/s。 如果我们能将业务处理时间压缩到 10ms, 32个core的服务器能够达到3200 requests/s。 因此业务处理的时间和我们服务器的性能息息相关